
AboutDockerProfessional illustrations
Docker Compose restart 指令詳解
好,等我哋詳細拆解下 Docker Compose restart 指令 點用同埋背後嘅原理。喺日常 容器管理 嘅工作中,無論你係 SRE 定係開發者,都實會遇到需要 重啟服務 嘅情況。唔好以為 docker compose restart 就係簡單噉將個 容器 熄咗再開返咁簡單,其實佢同 docker-compose down 跟住 docker-compose up 呢套組合拳有好大分別,亦都同直接喺 Docker CLI 用 docker restart 有啲微妙差異。呢個指令主要係針對你喺 docker-compose.yml 檔案裏面定義好嘅 服務 嚟進行操作,最適合用喺你想 重啟容器 但係又唔想影響到已經掛載好嘅 volumes,或者唔想重新構建鏡像嘅時候。
首先,你要明白個指令嘅基本用法。假設你個 docker-compose.yml 入面定義咗一個叫 webapp 同另一個叫 database 嘅服務,如果你淨係想 重啟 個 webapp,你可以喺 terminal 打 docker compose restart webapp。咁樣做,個 webapp 容器 會先收到一個 SIGTERM 信號,等佢有少少時間優雅噉關閉,跟住再即刻啟動返。但係,如果你乜都唔指定,直接打 docker compose restart,咁佢就會將你成個 project 裏面所有運行緊嘅 服務 全部 重啟 一次,呢個就係 多容器管理 嘅方便之處。呢個過程唔會重新拉取 鏡像,亦都唔會重新創建容器,所以速度會快好多,尤其適合喺你修改咗某啲設定檔案,而個設定已經透過 volumes 映射入容器內部,只需要個程式重新讀取嘅情況。
不過,有啲情況用 restart 未必係最好。譬如你個 容器 本身已經死咗,或者處於 Exited 嘅 容器狀態,你用 docker compose restart 係唔會令到佢起死回生嘅,因為佢只會對正在運行 (running) 狀態嘅容器生效。呢個時候,你可能需要考慮用 docker compose up 呢類命令。另外,同 docker-compose down 嘅分別就更加大喇:down 會將所有 容器、網絡同埋預設嘅匿名 volume 都剷走,成個環境還原,之後你要行 up 先可以重新開始。而 restart 就完全唔會掂到網絡同 volume 嘅設定,純粹係重啟過程。所以,當你喺度做 容器編排 時,一定要清楚自己嘅目的係想更新程式定係想徹底清理環境。
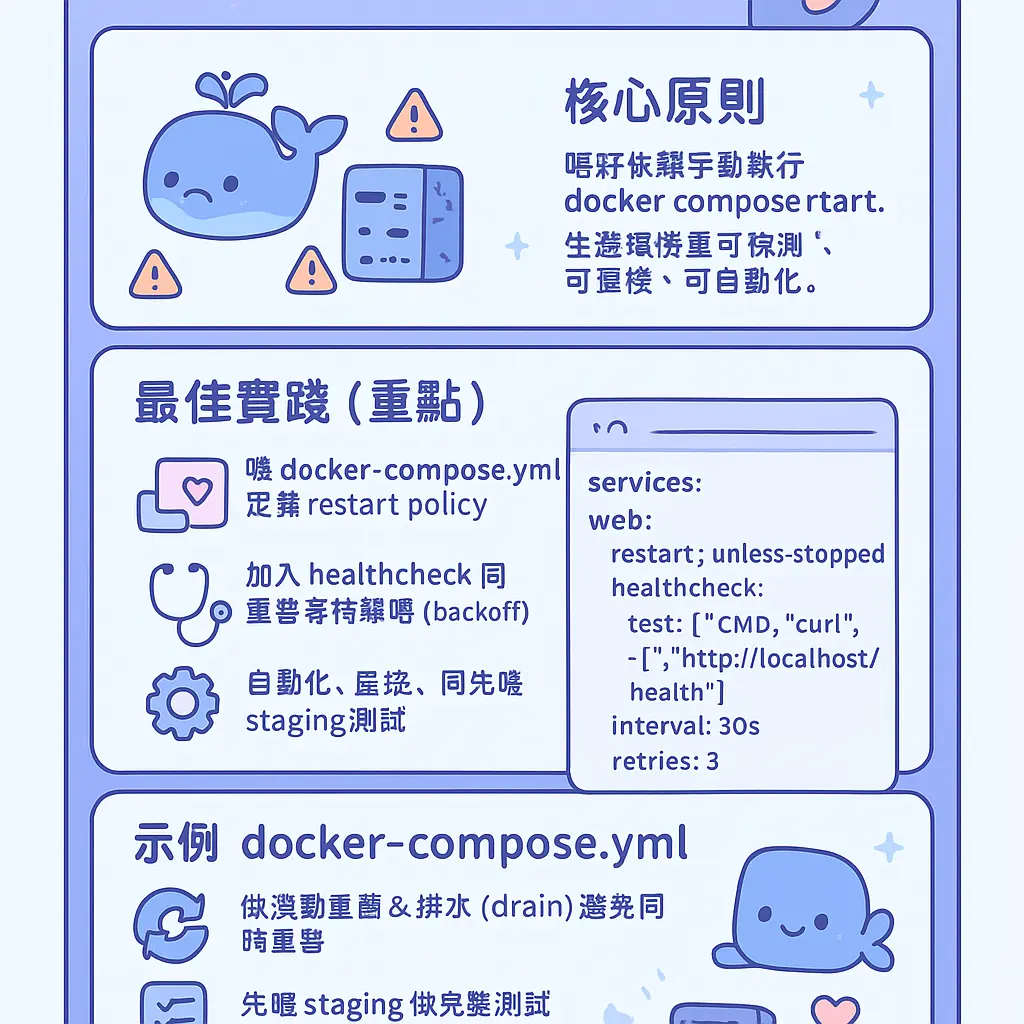
講到重啟,就不得不提 docker-compose.yml 裏面可以設定嘅 restart policy(重啟策略)。呢個策略係控制緊 容器 喺乜嘢情況下會自動 重啟,而唔使你手動打命令。常見嘅選項有 no(默認,唔自動重啟)、always(無論乜原因退出都重啟)、on-failure(只有非零退出碼先重啟)、同埋 unless-stopped(除非你手動 停止容器,否則都會自動重啟)。呢個策略係喺你行 docker compose up 嘅時候就已經生效,同你之後手動執行 docker compose restart 係兩套獨立機制。設定得好,可以大大增強服務嘅韌性,尤其係用 unless-stopped,就算成個 Docker daemon 重啟,你嘅服務都會跟住自動翻生,好適合用喺生產環境。
最後,俾啲實用建議你。如果你發現某個服務有 memory leak 或者行為古怪,第一時間用 docker compose restart [服務名] 係一個快速止血嘅好方法,因為佢唔會影響到同一個 compose project 入面其他服務,做到局部 重啟服務。另外,記得要善用 docker compose logs [服務名] 喺重啟前後睇清楚 log,確認問題。對於更加複雜嘅 重啟容器 需求,例如想一次過重啟所有服務但係要有先後次序,你就要喺 docker-compose.yml 裏面用 depends_on 配合 restart 指令去控制。總而言之,docker compose restart 係 Docker Compose 工具鏈裏面一個簡單但強大嘅 容器管理 指令,理解清楚佢同其他 down命令、up命令 嘅分別,可以令你喺管理 多容器 應用時更加得心應手。

AboutComposeProfessional illustrations
2026年最新 restart 實戰教學
好啦,各位開發同SRE嘅朋友,今次我哋就深入講下2026年最新嘅 Docker Compose restart 實戰教學。喺實際操作環境入面,識得靈活運用 restart 相關指令,絕對係 容器管理 嘅基本功,唔單止可以幫你慳返唔少時間,更重要係確保你嘅服務穩定性。好多初學者可能仲係停留喺「有問題就手動 docker stop 再 docker restart」嘅階段,但當你管理緊一個由多個服務組成嘅系統時,咁樣做就太冇效率啦。所以,我哋要善用 Docker Compose 呢個 容器編排 工具,佢可以幫你一次過處理晒所有 容器 嘅生命週期。
首先,你一定要搞清楚幾個核心概念同指令。最基本嘅 重啟容器 動作,你可以直接用 Docker CLI 嘅 docker compose restart 命令。呢個命令會重新啟動你 docker-compose.yml 檔案入面定義咗嘅所有服務,或者你可以喺後面指定某個服務名,只重啟個別服務。佢嘅好處係速度快,唔會刪除同重建容器,容器入面嘅檔案改動(如果冇用 volumes 持久化)同埋運行狀態可能會保留,但呢個亦係佢嘅風險,有時啲古怪問題就係咁樣殘留落嚟。所以,2026年嘅最佳實踐通常建議,如果係想進行一次「乾淨」嘅重啟,尤其係更新咗 鏡像 之後,更應該考慮用 docker compose up --force-recreate。呢個命令會停止舊容器,並根據最新配置重新創建新容器,確保環境一致性。
不過,講到 restart,點可以唔提 restart policy(重啟策略)呢?喺你嘅 docker-compose.yml 檔案入面,預先定義好重啟策略,先至係真正體現 容器編排 智慧嘅地方。常見策略有 no(默認,唔自動重啟)、always(無論點都會重啟)、on-failure(只有當容器非正常退出,即退出碼非0時先重啟)、同埋 unless-stopped(除非你手動停止,否則都會自動重啟)。例如,你個數據庫服務緊要過天,你就可以設 restart: always;而一啲一次性嘅批處理任務,就應該設 restart: "no"。喺2026年,隨著 Docker Hardened Images 嘅普及,配合精準嘅重啟策略,可以大大增強容器嘅韌性。記住,策略係寫喺服務定義下面,唔好同 docker compose restart 呢個命令搞亂。
當然,實戰環境千變萬化,有啲情況你需要徹底推倒重來。例如,你想連同 volumes 一齊清埋,或者網絡配置亂咗,咁你就需要用到組合拳。docker compose down 呢個命令就係你嘅好朋友,佢會停止並移除所有容器、網絡(默認),但會保留 volumes 同埋鏡像。跟住你再行 docker compose up -d,就等於一次完整嘅重啟。如果你想連 volumes 都清埋(危險動作,數據無回頭!),就要加 -v 參數,即係 docker compose down -v。呢個流程喺開發環境測試配置,或者喺 鐵人賽 中快速重置環境時非常有用。
最後分享幾個2026年常見嘅實戰場景同貼士。第一,當你修改咗 docker-compose.yml 檔案本身,例如更新咗環境變數或者端口映射,單純 restart 係唔會生效嘅,你必須要行 docker compose up -d 先得,因為佢會重新讀取配置。第二,監控 容器狀態 好重要,你可以用 docker compose ps 來睇吓各個服務嘅狀態同埋退出碼,特別係設定咗 on-failure 重啟策略時,呢個命令可以幫你診斷問題。第三,參考官方 Docker Docs 永遠係最準確,雖然 CSDN、iT邦幫忙 或者 Medium 上面有好多前人心得(好似 Cancerpio、NOJ 呢啲技術博客作者都寫過深入分析),但官方文檔係追得最貼最新功能嘅。希望呢段 2026年最新 restart 實戰教學 可以幫你更自信咁管理你嘅 多容器管理 應用啦。
About容器Professional illustrations
up 同 restart 有咩分別?
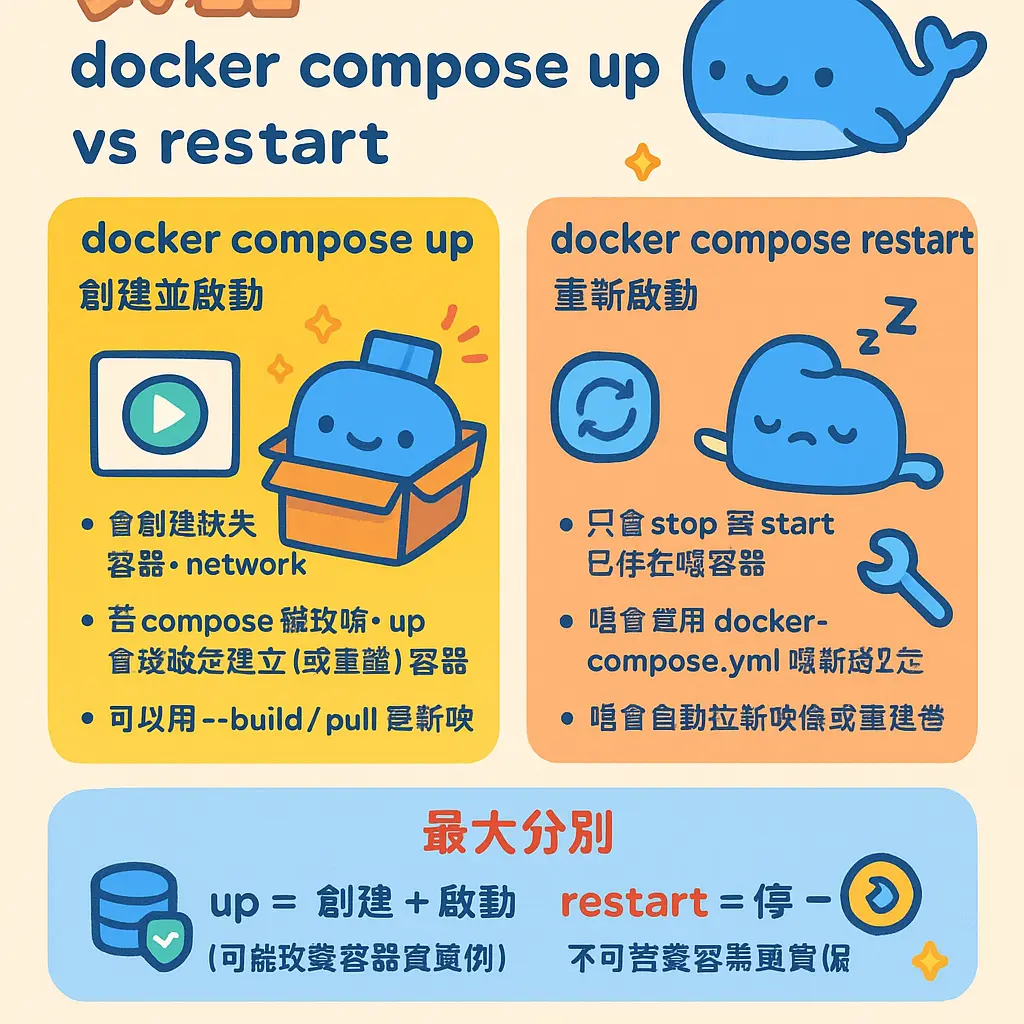
好喇,而家我哋就深入拆解下 Docker Compose 入面 up 同 restart 呢兩個命令,究竟有咩分別。好多初學 容器編排 嘅朋友,甚至係一啲有經驗嘅 SRE,有時都會撈亂,以為佢哋做緊類似嘅嘢,但其實背後嘅邏輯同影響可以好唔同。簡單嚟講,docker compose up 係一個「創建並啟動」嘅過程,而 docker compose restart 就純粹係一個「重新啟動」嘅動作。呢個分別,直接影響到你管理緊嘅 容器 同 服務 嘅狀態、數據,同埋你個 docker-compose.yml 檔案嘅定義會唔會被應用。
首先,我哋睇下 docker compose up 呢個命令。當你喺 terminal 打呢句嘢嘅時候,Docker Compose 會做一連串嘅工作。佢首先會去檢查你個 project 入面定義咗嘅 服務,跟住會去睇下相關嘅 鏡像 存唔存在,如果冇,佢就會根據設定去拉取 (pull) 或者構建 (build) 個鏡像。之後,佢會按照 docker-compose.yml 嘅設定,去創建 容器、網絡 (networks)、同 volumes 等等。如果個 容器 之前已經存在但係停止咗 (stopped),up 命令會重新啟動呢個現有嘅 容器,而唔係重新創建一個。呢個係一個好關鍵嘅點:up 會確保你嘅 服務 達到 YAML 檔案所描述嘅「目標狀態」。換句話說,如果你改咗 docker-compose.yml 入面嘅環境變數或者端口映射,再行 up,佢係會重新創建 容器 嚟應用呢啲新設定㗎!所以,up 命令其實係你整個 多容器管理 工作流嘅核心,由零開始建立環境,或者將現有環境更新到最新設定,都係靠佢。
咁 docker compose restart 又係咩玩法呢?呢個命令就簡單直接好多。佢唔會去檢查 鏡像 有冇更新,唔會重新構建鏡像,亦都唔會重新讀取同應用 docker-compose.yml 入面嘅新配置。佢做嘅嘢,純粹係向你指定嘅、已經在運行中或者已經停止咗嘅 容器,發送一個重啟信號。個過程就好似你喺一部電腦上面,撳個「重新開機」掣一樣。個 容器 裏面嘅進程會收到停止信號,優雅地結束,然後再重新啟動。但係,個 容器 本身嘅 ID、網絡配置、掛載嘅 volumes 數據,全部都會保持不變。呢個命令主要用喺咩情況呢?例如你個應用程式嘅代碼有熱重載 (hot reload) 功能,或者你只係想快速重啟某個 服務 嚟解決一個暫時性嘅小問題,又或者係你修改咗某啲設定檔並已經用 volumes 掛載入去,想重啟嚟生效。佢嘅動作好快,因為跳過咗所有資源創建同檢查嘅步驟。
舉個實際例子嚟說明個分別。假設你有一個 WordPress 網站,用 Docker Compose 管理,裏面有 wordpress 同 mysql 兩個 服務。你發現個網站有啲怪,懷疑係 PHP 進程有問題,於是你就行 docker compose restart wordpress。呢個時候,只有 wordpress 呢個 容器 會重啟,mysql 容器 完全唔受影響,而且所有網站數據(因為用緊 volumes)都原封不動。重啟完,問題可能就解決咗。但係,如果你係收到安全通告,要更新 WordPress 嘅 鏡像 版本,你改咗 docker-compose.yml 裏面個 image tag,例如由 wordpress:6.4 改成 wordpress:6.6。呢個時候,你行 restart 係完全冇用嘅,因為佢唔會去拉取新嘅 鏡像。你必須要行 docker compose up -d,個 up 命令偵測到 image tag 唔同咗,就會拉取新鏡像,停止並移除舊嘅 容器,然後用新鏡像創建一個新嘅 容器。呢個先係正確嘅更新流程。
另外,仲要提一提同其他命令嘅關聯。有時人會混淆 restart 同 stop 再加 start 嘅組合。docker compose stop 只係停止 容器,但唔移除;跟住你行 start,就可以用返原有配置啟動返。呢個組合同 restart 效果類似,但 restart 係一個原子操作。而 docker compose down 就犀利喇,佢會停止 容器 並且 移除 佢哋(通常仲會移除網絡),成個環境會被拆解。之後你再行 up,就等於由頭嚟過。所以,down 同 up 經常被視為一對,用嚟徹底重置環境;而 restart 就係一個輕量級嘅、原地嘅重啟操作。
最後,不得不提 restart policy,即係重啟策略。呢個係寫喺 docker-compose.yml 裏面嘅設定,例如 unless-stopped 或者 on-failure。呢個策略係由 Docker 守護進程 (daemon) 控制,同 docker compose restart 呢個手動命令係兩回事。設定咗 restart policy 之後,就算你部主機重啟,Docker 都會自動幫你啟動符合策略嘅 容器。而手動嘅 restart 命令,就係你即時想觸發一次重啟嘅手段。理解清楚 up 同 restart 嘅分別,可以幫你更精準、更有效率咁管理你嘅 容器 同 服務,避免喺不必要嘅時候重建 容器 導致停機時間變長,或者喺需要更新配置時用錯命令而冇生效。記住,up 係關於「狀態同設定」,restart 只係關於「進程」。

About服務Professional illustrations
docker restart vs compose restart
好啦,各位開發同SRE朋友,今次我哋就深入傾下「docker restart」同「docker compose restart」呢兩個命令嘅分別。好多初學Docker嘅朋友,甚至係有啲經驗嘅工程師,都可能唔係好清楚幾時用邊個,或者以為佢哋嘅效果係一樣。其實,呢兩個命令背後嘅哲學同操作對象完全唔同,用錯咗隨時搞亂你個容器編排環境,甚至整唔見咗啲數據㗎。
首先,我哋要搞清楚最基本嘅概念:「docker restart」係Docker CLI嘅原生命令,佢操作嘅對象係單一個容器。就好似你屋企有部獨立嘅冷氣機,你撳個掣就只係重開呢一部機。呢個命令好直接,就係向指定嘅容器發送一個重啟信號,等個容器內部嘅進程重新行過。但係,佢有個好關鍵嘅限制:佢完全唔會理會你個容器之間嘅依賴關係同啟動順序。例如,你個應用係由一個PostgreSQL容器同一個Web App容器組成,如果你用「docker restart」只係重開個Web App,但係個Database容器喺重啟期間有咩閃失或者連線問題,你個Web App一開返就可能即刻報錯,因為連唔到Database。所以,docker restart 比較適合用喺單一容器、快速測試某個設定更改、或者係好獨立嘅服務上面。
咁「docker compose restart」又係咩玩法呢?呢個命令係屬於Docker Compose呢個容器編排工具嘅一部分。佢操作嘅對象唔係單一容器,而係你喺「docker-compose.yml」檔案裏面定義嘅服務。呢個係一個超級重要嘅分別!Docker Compose嘅設計就係為咗管理多容器應用,一個服務可以包含一個或者多個相同鏡像嘅容器實例(如果你有做擴展嘅話)。當你執行「docker compose restart」嘅時候,Compose會根據你個YAML檔案嘅定義,去處理相關嘅服務。佢嘅好處在於,佢會尊重你喺「docker-compose.yml」裏面設定嘅依賴關係(depends_on)。雖然佢唔會好似「docker compose up」咁重新建立容器,但喺重啟嘅流程上,Compose工具本身對多容器管理有更好嘅掌控。
舉個實際例子啦。假設你有一個「docker-compose.yml」,裏面定義咗三個服務:一個「db」(數據庫)、一個「backend」(後端API)、一個「frontend」(前端)。你喺「backend」同「frontend」嘅設定裏面,用咗「depends_on」指明要等「db」

AboutcomposeProfessional illustrations
點解 restart 後服務無反應?
好多時我哋用 Docker Compose restart 命令之後,發現個服務好似「死咗」咁,完全無反應,真係會搞到人好炆。其實呢個問題背後有好多可能性,唔單止係 restart 命令本身咁簡單,好多時同我哋個 docker-compose.yml 設定、容器狀態、甚至係入面跑緊嘅應用程式有莫大關係。首先,你要搞清楚你係用緊邊種 restart 方法。好多人會直接喺 terminal 打 docker-compose restart,以為咁就搞掂,但呢個命令其實只係向 compose file 入面定義嘅容器發送一個重啓信號,等於係逐個容器做 docker restart。如果個容器本身已經死咗,或者個 entrypoint script 有問題,咁 restart 完個服務都係唔會正常行返,因為個根本問題無解決到。
其中一個最常見嘅死因,就係同 restart policy 設定有關。喺 docker-compose.yml 入面,你可以為每個服務設定 restart policy,例如係 no, always, on-failure, 同 unless-stopped。如果你 set 咗 no,咁你手動 stop 咗個容器之後,用 docker-compose restart 係唔會令佢自動行返嘅。又或者你 set 咗 unless-stopped,咁當你曾經用 docker-compose down 或者 docker stop 命令明確停止過個容器,之後就算你 restart 個 compose project,佢都唔會自動行返,呢個設計係為咗防止你唔小心將啲本來想停用嘅服務又開返。所以,當你發現 restart 無反應,第一時間應該去檢查吓個 compose file 入面有無設定 restart policy,同埋理解清楚每個 policy 嘅行為。好似 unless-stopped 呢個設定,喺 2026 年嘅 Docker Docs 同埋好多 SRE 嘅分享入面,都仲係一個好容易令人中伏嘅位。
另一個大問題可能出喺 volumes 或者 bind mounts 嘅狀態度。假設你個服務(例如係個 database)依賴一個 volume 去儲存數據,而呢個 volume 入面嘅數據可能已經損壞,或者權限出錯。當你 restart 個容器時,佢會重新掛載同一個 volume,如果入面嘅數據係壞嘅,咁個服務程式可能一啟動就 crash,令到你睇落去好似無反應。同樣地,如果你用 bind mount 將 host 機上面嘅 directory map 入去容器,而 host 上面個 directory 嘅檔案被刪除或者改咗權限,都會導致容器入面嘅應用程式啟動失敗。呢類問題唔係單純 restart 可以解決,你需要檢查容器嘅 logs,用 docker-compose logs 服務名 去睇吓啟動過程有無 error message,然後再針對數據同檔案進行修復。
仲有,唔好忽略咗「鏡像」本身嘅問題。你可能用緊一個有問題嘅 Docker 鏡像,或者個鏡像嘅 tag 被更新咗(例如 latest tag 指向咗一個新版本),而新版本同你嘅設定檔唔兼容。當你執行 docker-compose restart,佢係唔會重新拉取鏡像嘅,佢只會用返現有嘅本地鏡像去重啓容器。如果個本地鏡像本身有 defect,或者入面嘅應用程式有 bug,咁 restart 幾多次都無用。解決方法可以係先做 docker-compose down,然後確保用 docker-compose pull 拉取最新嘅鏡像(如果適用),再用 docker-compose up -d 去重新建立同啟動容器。呢個過程先會確保用到正確嘅鏡像檔案。另外,近年多咗人講嘅 Docker Hardened Images 概念,都係想減少呢類因鏡像問題導致服務不穩嘅情況。
網絡同依賴關係都係隱形殺手。Docker Compose 嘅精髓就係「容器編排」,幫你管理多個有關係嘅容器。如果你個服務(例如一個 web app)依賴另一個服務(例如個 database),而你呢個 dependency 無設定好 healthcheck 或者 restart 次序,當你 restart 個 web app 時,個 database 可能仲未準備好接受連線,導致 web app 啟動失敗。雖然 restart 命令會按 compose file 入面嘅定義次序去重啓容器,但佢唔會等待依賴服務「準備好」。呢個時候,你可能需要更精細嘅控制,例如先用手動方式確保依賴服務已經行緊同狀態健康,先至去處理有問題嘅服務。或者,喺編寫 docker-compose.yml 時,就要善用 depends_on 配合 condition 設定,去確保啟動次序。
最後,亦都可能係最簡單嘅原因:你誤會咗個服務嘅狀態。有時你用 docker-compose restart 之後,好心急咁用瀏覽器去 access 個 service,但係個應用程式本身需要一段比較長嘅時間去初始化(例如載入一個好大嘅數據庫)。喺呢段時間內,個容器進程係存在嘅,但係服務端口未 listen,或者未準備好處理請求,所以你會覺得「無反應」。你可以用 docker-compose ps 命令去檢查容器狀態,如果狀態係 Up,咁就可能只係需要等待。亦可以用 docker-compose logs --follow 去即時監察啟動日誌,睇吓佢卡喺邊一個步驟。記住,restart 並唔係萬能藥,佢只係一個觸發重新運行嘅動作。如果個根本問題係喺應用程式邏輯、設定錯誤、資源不足(例如 memory limit)或者 host 系統問題,咁 restart 幾多次都係徒勞。真正嘅解決之道,係要識得利用 Docker CLI 同 Docker Compose 提供嘅工具,去診斷同理解你嘅容器同服務究竟處於咩狀態,再對症下藥。
AboutDockerProfessional illustrations
restart 指令參數全解析
好喇,而家我哋就深入拆解下 docker compose restart 呢個指令入面,究竟有咩參數可以玩,同埋點樣用先至最精明。好多初學嘅朋友,甚至係有啲經驗嘅 SRE,都可能只係識打 docker compose restart 就算,但其實背後有唔少細節可以調校,直接影響到你容器編排嘅流暢度同穩定性。
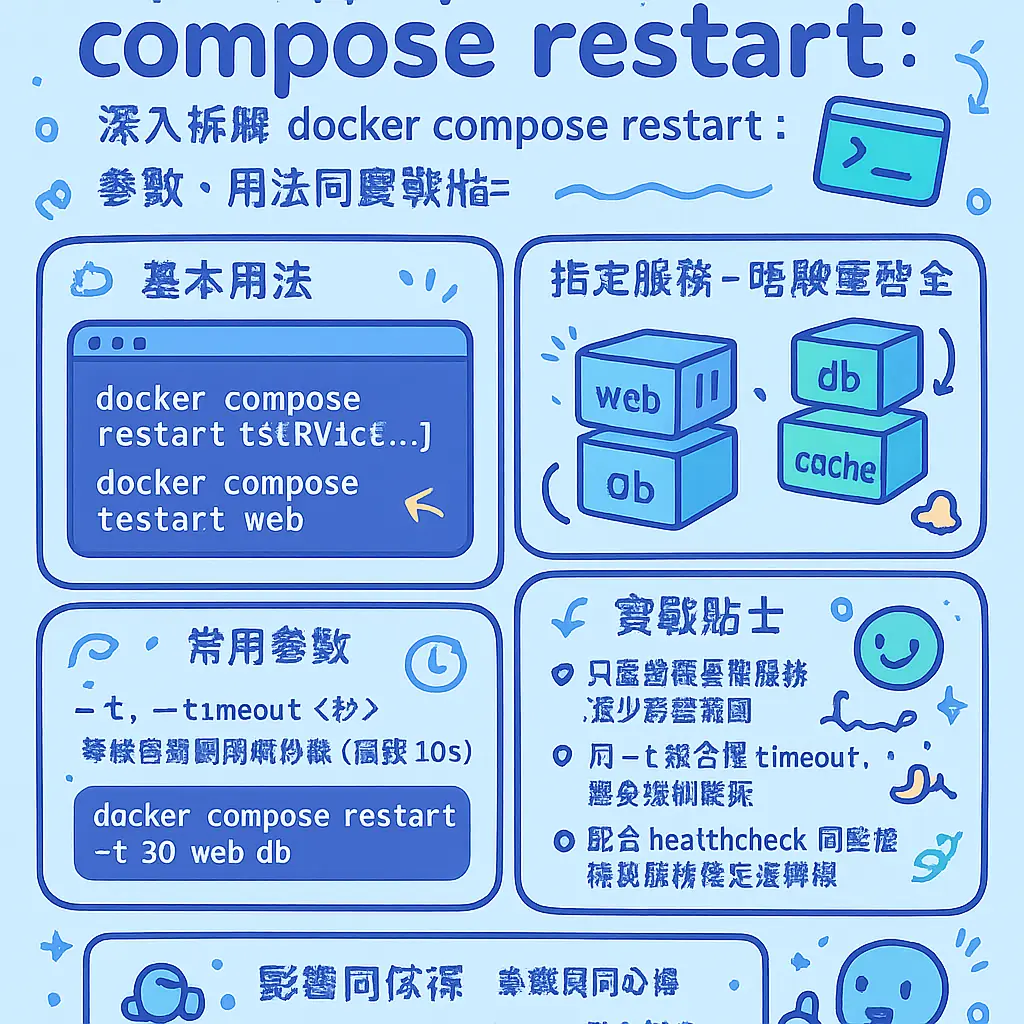
首先,最基本嘅用法就係指定要重啓邊個服務。你唔係一定要重啓成個 docker-compose.yml 裏面所有嘢嘅。假設你個 compose file 定義咗 web、db、cache 三個服務,但係你只係改咗 web 服務嘅設定,咁你完全冇必要搞到個 database 都停一停。你呢個時候就可以用 docker compose restart web,咁就只會重啓 web 呢個容器,其他服務繼續行,唔會受影響。呢個對於多容器管理嚟講好重要,可以做到最小干擾。如果你要重啓多過一個服務,只要喺後面逐個名空格隔開就得,例如 docker compose restart web cache。
跟住,就要講一個好關鍵但成日被人忽略嘅參數:--timeout 或者 -t。呢個參數係用嚟設定等待容器優雅停止嘅時間,單位係秒。默認值係 10 秒。咩意思呢?當你執行 restart 指令,Docker Compose 其實係先向容器發送一個 SIGTERM 信號,等佢有時間處理完手頭上嘅工作(例如完成緊嘅資料庫交易、寫完 log 檔)先自己關閉。如果過咗你設定嘅 timeout 時間,容器都仲未停,咁 Docker 就會唔客氣,發出 SIGKILL 信號去強制殺死個進程。所以,如果你個應用程式需要長啲時間去清理現場,你就要將個 timeout 設大啲,例如 docker compose restart --timeout 30 web,俾足 30 秒佢。相反,如果你想快啲,可以設細啲,但要小心資料損毀嘅風險。
另外,有一點必須要釐清:docker compose restart 同 docker restart 係兩個層面嘅指令。後者係 Docker CLI 直接用嚟重啓單一個容器,而前者係 Docker Compose 工具用嚟操作你 compose file 裏面定義嘅服務。更重要嘅係,restart 指令同 docker-compose.yml 裏面可以設定嘅 restart policy 係兩回事,好多人會混淆。Restart policy(例如 unless-stopped、on-failure)係 Docker 引擎自己管理嘅策略,決定容器喺乜嘢情況下(例如主機重啓、進程退出)自動重啓。而我哋而家講嘅 docker compose restart 係一個手動、明確嘅操作指令,唔會影響到你喺 YAML 檔 set 好嘅自動重啓策略。
講到實際應用,你可能會問,咁同 docker compose down 跟住 docker compose up 有咩分別呢?分別好大!down 指令會停止並移除容器、網絡(除非特別標明保留),但默認唔會移除 volumes 同埋鏡像。如果你用 down 再 up,個服務會由頭建立過,雖然 volumes 嘅數據可能仲喺度,但個過程會耐啲。而 restart 就純粹係將現有運行緊嘅容器停止再啟動,唔會移除再創建,所以速度快好多,亦唔會影響到容器嘅網絡同儲存配置。不過,要留意 restart 並唔會重新加載你修改咗嘅 docker-compose.yml 設定或者更新咗嘅鏡像。如果你改咗環境變數或者綁定咗新嘅埠,必須要用 up --detach 先會生效。
最後提多個小貼士,尤其係管理生產環境嘅朋友。當你執行 docker compose restart 嘅時候,最好配合監控工具一齊睇住,觀察吓容器狀態同應用日誌,確保重啓過程順利,冇出現意料之外嘅錯誤。因為 restart 始終會造成服務極短暫嘅中斷,雖然好過 down/up,但都要揀啱時間同有準備去做。將呢啲參數同用法學識,你對容器管理嘅掌握就會更加得心應手,唔使下下都係粗暴地剷走晒啲嘢再嚟過。
AboutDockerProfessional illustrations
點樣優雅重啟容器服務?
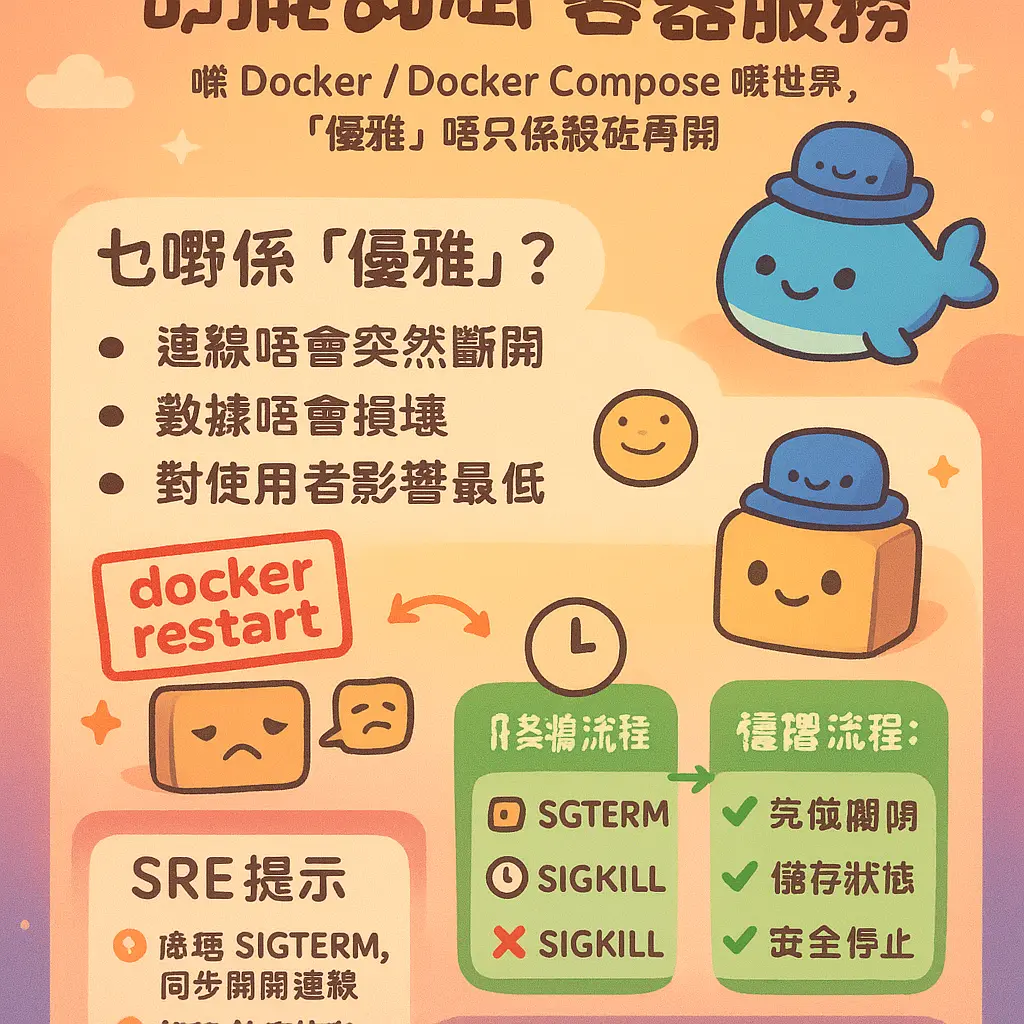
講到點樣優雅重啟容器服務,我哋首先要搞清楚「優雅」係咩意思。喺 Docker 同 Docker Compose 嘅世界入面,優雅重啟並唔係就咁 kill 咗個 process 再開咁簡單,而係要確保服務嘅連線唔會突然斷開、數據唔會損壞,同埋整個重啟過程對使用者嘅影響減到最低。呢個對於做 SRE 或者負責線上服務嘅朋友嚟講,真係重中之重。好多新手可能一嚟就喺 Docker CLI 打 docker restart 或者 docker-compose restart,咁樣雖然係會重啟到個容器,但其實唔算得上係「優雅」,因為佢哋本質上係先發 SIGTERM 信號,等一陣如果個容器唔自己停,就會強制發 SIGKILL,咁樣好容易會導致啲正在處理嘅請求失敗,尤其係啲數據庫或者有狀態服務,真係分分鐘炒車。
所以要真正做到優雅,我哋要從幾個層面去諗。第一,係善用 Docker Compose 本身嘅 restart policy。喺你個 docker-compose.yml 檔案入面,你可以為每個服務設定重啟策略,例如係 restart: unless-stopped 或者 restart: on-failure。設定咗 unless-stopped,個容器就會喺除非你手動停止佢,否則無論咩原因退出(包括宿主機重啟)都會自動重啟返,咁樣可以保證服務嘅高可用性。而 on-failure 就只會喺容器非正常退出(即退出碼非0)嘅時候先至重啟。呢啲策略係由 Docker 引擎自己管理,屬於一種被動式嘅、自動恢復嘅優雅,對於處理意外停止好有用。不過要留意,呢個 policy 同我哋主動想重啟服務嚟更新配置或者鏡像,係兩回事嚟。
第二,主動進行服務重啟嘅標準優雅流程。當我哋更新咗代碼或者配置,需要重新拉取最新嘅 Docker Hardened Images 或者自己 build 嘅鏡像時,最常見同推薦嘅做法係使用 docker compose down 配合 docker compose up 呢個組合。但係,直接 down 會停止並移除容器,如果冇設定好 volumes 嘅管理,可能會搞到數據無咗。所以,更精細嘅做法係:首先,用 docker compose stop 去溫柔地停止相關嘅服務容器,呢個命令會向容器發送 SIGTERM,等佢有時間完成手頭上嘅工作同清理資源。跟住,我哋可以先拉取新鏡像(docker pull),或者重新 build(docker compose build)。最後,再用 docker compose up -d 去重新創建並啟動容器。因為 Docker Compose 會重用之前定義嘅 volumes,所以數據通常會得以保留。呢個流程比起一刀切嘅 restart 命令,對服務嘅衝擊細好多。
第三,進階嘅滾動更新與零停機策略。對於真正要求高可用、零停機嘅生產環境,單靠重啟單一容器係唔夠嘅。我哋需要考慮到容器編排嘅思維。雖然 Docker Compose 本身唔係完整嘅編排器,但我哋可以透過一啲技巧嚟模擬。例如,你可以設定多個實例(scale),然後逐個重啟佢哋,確保總有容器係可以處理請求。具體可以點做?你可以先用 docker compose up -d --scale your_service=2 去啟動兩個實例,當你需要更新時,就逐個對容器進行操作:先停止一個(docker stop),等佢完全退出後,再用 docker compose up -d 啟動一個新版本嘅實例,然後先至處理下一個。咁樣,服務就永遠至少有一個實例在線,達到零停機重啟。當然,呢個方法需要你嘅應用程式支援無狀態或者能夠處理好 session 同數據同步,同埋背後嘅負載均衡要設定正確。
另外,不得不提嘅係點樣確保重啟過程入面數據嘅完整性,尤其係當你使用緊 volumes 去持久化數據嘅時候。喺執行 docker compose down 之前,真係要百分百確認你嘅數據 volume 係有被正確定義同埋唔會被移除。喺 down 命令入面,預設係唔會移除 volume 嘅,但如果你手多加咗 -v 參數,咁就真係喊都無謂。所以,最佳實踐係將重要數據 volume 嘅聲明獨立出嚟,用 external 或者明確嘅 volume 定義,避免誤操作。
最後,想講下監控同驗證。重啟完唔係就完事㗎!你要點樣知道個服務係咪真係優雅重啟成功?除咗睇吓個容器狀態係 Up 之外,更重要係要檢查應用日誌,睇下有冇啲異常錯誤,同埋用健康檢查端點(如果有的話)去確認服務已經完全就緒。Docker Docs 同好多技術社區好似 Medium、CSDN、iT邦幫忙或者 SRE 相關嘅分享,都不斷強調監控同可觀測性嘅重要性。重啟只係手段,確保服務穩定先係目的。
總括呢段嚟講,優雅重啟容器服務係一個結合咗正確工具使用(Docker CLI / Docker Compose)、策略設定(restart policy)、流程規劃(停止、更新、啟動)同埋架構設計(多實例、數據持久化)嘅綜合課題。唔好再求其打個 restart 命令就算,花少少時間設定好你嘅 docker-compose.yml 同埋重啟流程,長遠嚟講可以避免好多半夜起身處理故障嘅噩夢。記住,容器管理嘅藝術,在於點樣喺動態同變化之中,維持服務嘅平穩與可靠。

AboutHardenedProfessional illustrations
restart 常見錯誤同解決方法
講到用 Docker Compose restart 呢個指令,好多工程師同 SRE 都試過撞板,明明好簡單嘅指令,點知一 run 就出錯,搞到成個 容器編排 亂晒。呢度就同大家拆解幾個最常見嘅錯誤情境,同埋點樣快速解決。首先,最多人遇到嘅問題係,以為用 docker-compose restart 就等於重新載入咗個 docker-compose.yml 設定檔,其實唔係㗎!Restart 命令 純粹係將現有運行緊嘅 容器 逐個停低再開返,佢唔會讀取你改過嘅 yml 設定,亦都唔會重建 鏡像。如果你改咗 volumes 嘅設定或者環境變數,齋 restart 係唔會生效嘅,呢個時候你需要用 docker compose down 跟住再 docker compose up -d,先可以確保新設定被應用。好多新手喺 菜鳥教程 或者 iT邦幫忙 睇完基礎教學,就咁照搬,結果就中伏。
另一個常見錯誤係同 restart policy 設定有關。喺 docker-compose.yml 裡面,你可以設定 restart: always、restart: unless-stopped 或者 restart: on-failure。但係好多人唔知,呢個政策係喺容器意外退出時先會觸發,而唔係你用 Docker CLI 手動執行 docker stop 或者 docker compose stop 嘅時候。如果你手動停咗個服務,個政策係唔會幫你自動開返㗎。有啲團隊為咗確保服務高可用,會設定成 unless-stopped,但之後發現手動維護時好麻煩,呢個就要事先規劃好。另外,有啲情況係個 容器 本身啟動腳本有問題,導致不停咁 重啟容器,形成重啟迴圈,咁你就需要去檢查吓應用程式嘅 log 或者 entrypoint 設定。
仲有一類錯誤係同資源同狀態有關。例如,你執行 docker compose restart 時,有個別 服務 因為依賴其他服務而未準備好,結果 restart 後連線失敗。又或者係 volumes 被其他程序佔用咗,導致容器無法重新掛載。呢啲情況底下,你需要用 docker compose down 先完整停止並移除所有相關 容器,釋放資源,然後先再 up 過。記住,down 命令 會移除容器,但預設唔會剷走你嘅 volumes,如果你需要徹底清理,就要加 -v 參數,不過咁樣會刪埋數據,要好小心。
另外,網絡設定衝突都係常見死因。如果你用緊自定義網絡,而 restart 時個網絡名被佔用或者有衝突,個容器就可能起唔返。呢個時候可以試吓用 docker network prune 清理咗冇用嘅網絡,再重新啟動。同時,都要留意 Docker 本身嘅系統資源,好似係磁碟空間不足(特別係 Docker 儲存鏡像同紀錄嘅位置爆咗),或者係記憶體不足,都會令到 重啟服務 失敗。定期用 docker system df 檢查下空間使用情況係好習慣。
最後,不得不提嘅係版本同指令兼容性問題。到咗2026年,Docker Compose 嘅生態已經好成熟,但係仲有好多舊文章(例如 CSDN、Medium 或者 Cancerpio 上面嘅舊文)教你用 docker-compose restart 呢類舊式指令(有橫槓嘅)。由 Docker Compose V2 開始,官方推薦用 docker compose(空格)呢個格式。如果你仲用緊舊指令,可能喺新版本環境會遇到問題。所以,最好養成習慣,跟返 Docker Docs 官方最新文件嘅寫法,減少不必要嘅麻煩。總括來講,容器管理 同 多容器管理 唔可以死記指令,要理解每個指令背後做緊咩,同埋你當前嘅 容器狀態 係點,先可以避免呢啲常見錯誤,令到你嘅 容器重啓 過程順順利利。

AboutCSDNProfessional illustrations
自動重啟策略點設定?
講到自動重啟策略點設定,呢個真係 Docker Compose 管理容器服務嘅靈魂設定之一,尤其係當你部署一啲需要長期運行、唔可以成日死咗冇人理嘅服務嗰陣。簡單啲講,自動重啟策略(restart policy)就係你預先同 Docker Compose 講好:「喂,如果個容器因為某啲原因停咗,你應該點樣處理佢?」呢個設定直接寫喺你個 docker-compose.yml 檔案裏面,屬於服務定義嘅一部份。好多新手可能淨係識用 docker restart 或者 docker compose restart 呢啲手動指令,但其實設定好策略,系統就會自動幫你搞掂,慳返好多半夜起身救火嘅時間,對於做 SRE 或者系統管理嘅朋友嚟講,簡直係必學。
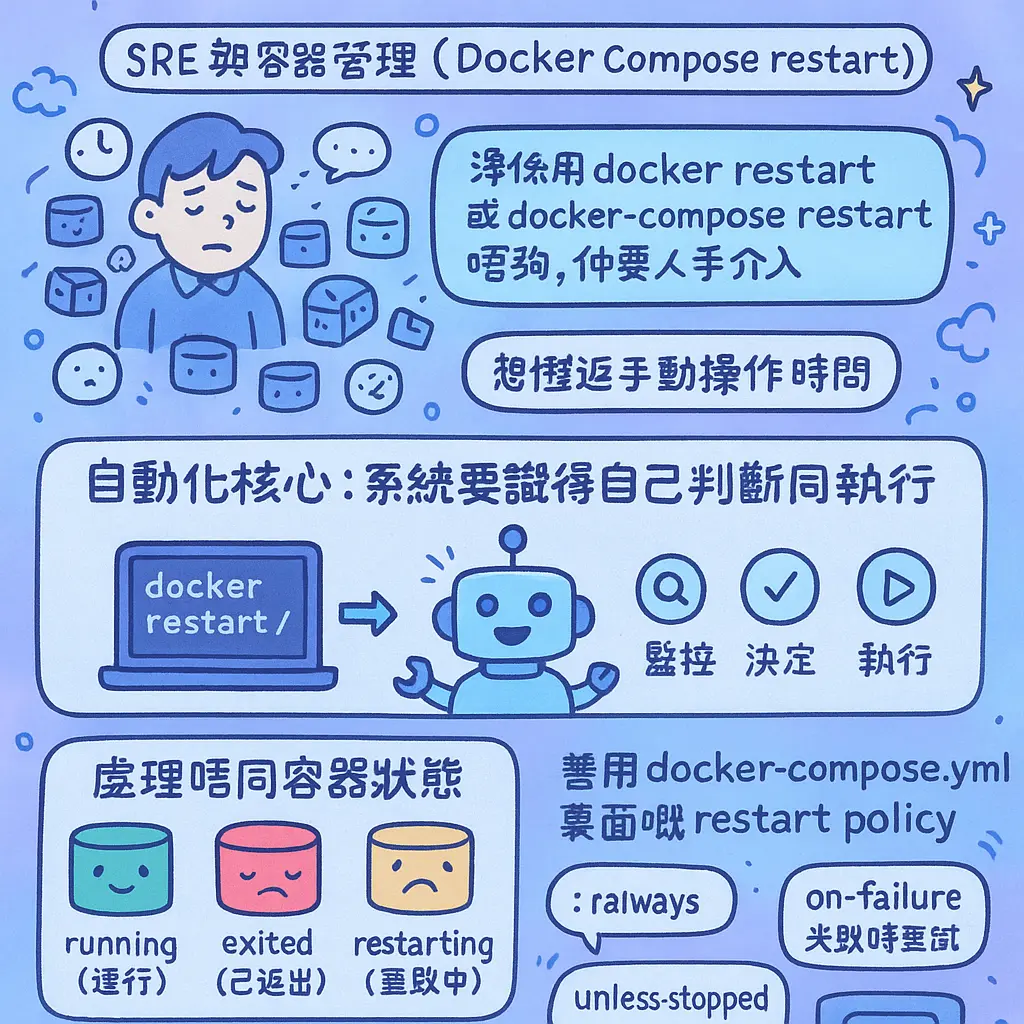
咁具體有邊幾種策略可以揀呢?主要係睇你個 restart 後面跟住咩參數。最常用嘅有以下幾種:第一種係 "no",即係話明唔自動重啟,無論個容器點樣退出都唔理,適合啲一次性任務或者你明確想手動控制嘅情況。第二種係 "always",即係話無論個容器點樣退出(就算係你手動用 docker stop 停咗佢),Docker Compose 都會重新啟動佢,呢個比較霸道,通常用喺真係絕對唔可以停嘅核心服務上,但你要小心,因為就算你想維護停機,佢都會不斷嘗試重啟,可能要用 docker compose down 或者改設定先停到。第三種係 "on-failure",呢個就聰明啲,佢只係當容器以非零嘅退出碼(即係代表失敗)結束嗰陣先會重啟,如果係正常停止(退出碼為0),就唔會重啟,好適合處理一啲預期會有偶然錯誤嘅任務。第四種係 "unless-stopped",呢個可以話係 "always" 嘅改良版,佢會自動重啟容器,除非你明確地用 docker stop 或者 docker compose stop 命令停止咗佢,之後就算成個 Docker 守護進程重啟,呢個容器都唔會自動開返,要你手動 up 返,呢個策略喺平衡自動化同手動控制方面幾好用。
設定嘅方法好簡單,就係喺你 docker-compose.yml 裏面,每個服務底下加個 restart 欄位。例如你有一個 web 服務,你想設定成 on-failure,最多重試 3 次,你可以咁樣寫(當然,我哋唔用代碼塊,就口語化描述下):喺 services 段落下面,有個叫 web 嘅服務,入面有 image、ports 呢啲設定,然後你加一行 restart: on-failure:3 就得。個數字代表最大重試次數。如果你用 unless-stopped,就直接寫 restart: unless-stopped。記住,改完 yml 檔案之後,你要運行 docker compose up -d 嚟應用更改,或者用 docker compose restart 去重新啟動現有服務。不過要留意,restart policy 係由 Docker 守護進程管理,唔係由 Docker Compose 直接管理,所以就算你離開咗 Compose 環境,只要個容器仲喺度,個策略都會生效。
點樣揀策略呢?就要睇你個容器嘅性質同埋你嘅運維目標。如果你個係數據庫服務,例如 MySQL 或者 PostgreSQL,通常會建議用 unless-stopped,確保服務意外死咗會自己翻生,但係當你需要進行計劃性維護、備份或者遷移嗰陣,你可以用 docker stop 命令明確停止佢,佢就唔會自己彈出嚟阻住你。如果你個係一個後台處理 worker,例如用嚟處理隊列任務,咁 on-failure 可能更合適,等佢任務失敗時自動重試,但成功完成後就安靜退出。至於 always,就要好小心用,因為佢真係好進取,有時會導致你想停都停唔到嘅尷尬情況,你可能要配合使用 docker rm -f 強制移除先得。另外,呢啲策略同 volumes 嘅設定都好有關係,因為重啟容器唔會影響到掛載嘅數據卷,所以你嘅數據通常係安全嘅,但都要確保你嘅鏡像(特別係啲 Docker Hardened Images)設計上能夠應付頻繁重啟。
最後,實戰上會有啲乜嘢常見陷阱同最佳實踐呢?首先,你要明白自動重啟唔係萬能,如果個容器係因為應用程式本身嘅 bug 或者配置錯誤而即時崩潰,咁設定 always 或者 on-failure 就會導致個容器不斷重啟、死亡、再重啟,形成一個重啟循環,咁樣反而會加重系統負擔。你可以用 docker ps 或者 docker compose ps 睇下容器狀態,如果見到個容器嘅 STATUS 成日顯示 "Restarting",就可能中咗招。其次,自動重啟策略同容器編排裏面嘅健康檢查(healthcheck)一齊用會更強大,你可以設定等個容器通過健康檢查先算佢真正啟動成功,避免服務未準備好就接收流量。另外,當你要徹底清理同重啟服務嗰陣,記得唔好淨係依賴 restart 策略,正確流程可能係先用 docker compose down 停止並移除所有容器、網絡,然後再 docker compose up -d 重新建立,咁樣可以確保一個乾淨嘅狀態。網上好多資源好似 Docker Docs、CSDN、Medium、iT邦幫忙嘅鐵人賽文章,或者菜鳥教程,都有深入討論呢啲進階用法,大家有興趣可以自己去搜尋下 "restart policy" 同 "容器管理" 呢啲關鍵詞去深入研究。總之,設定自動重啟策略係 Docker Compose 容器管理基本功,設定得好,可以大大提升你服務嘅韌性同穩定性,令你唔使成日做救火隊員。

AboutCancerpioProfessional illustrations
點樣監控 restart 後狀態?
好啦,當你用 Docker Compose restart 完啲服務之後,點樣確保佢哋真係正常運行呢?監控 restart 後嘅狀態,絕對唔係淨係望住個 terminal 睇吓有冇 error 咁簡單,而係要有一套方法去檢查容器嘅健康狀況、服務嘅連通性同埋日誌係咪正常。作為一個 SRE 或者開發者,呢個步驟好關鍵,可以避免啲服務「假啟動」——即係個容器行緊,但裏面個應用程式其實死咗或者連唔到數據庫。
首先,最直接嘅方法就係用 Docker CLI 嘅幾個基本命令。你可以用 docker compose ps 嚟睇吓所有由你個 docker-compose.yml 管理嘅容器,佢會清楚顯示每個容器嘅狀態(例如係 Up、Exited)、運行咗幾耐同埋佢哋嘅端口映射。呢個係一個快速嘅概覽。跟住,如果你想深入啲睇某個特定服務,可以用 docker compose logs [服務名],重點睇吓 restart 之後嘅最新日誌有冇出現 exception 或者 error message。好多時,應用程式啟動失敗嘅原因,例如係 database 連線問題或者某個 volumes 掛載嘅設定檔出錯,都會喺日誌度即時反映。記住,睇日誌唔好淨係睇尾幾行,最好跟住個時間戳,睇吓 restart 命令執行之後嘅所有輸出。
不過,齋睇日誌同狀態可能唔夠全面。進階啲嘅做法,係要善用 Docker 本身提供嘅健康檢查(Healthcheck)功能。你可以喺 Dockerfile 或者直接喺 docker-compose.yml 裏面,為每個服務定義一個 HEALTHCHECK 指令。例如,你可以設定一個指令,等個容器啟動後,定期用 curl 去 call 自己個應用程式嘅 /health endpoint,或者檢查某個特定嘅 process 係咪存在。咁樣之後,當你再用 docker compose ps 嘅時候,你會見到多咗一欄「STATUS」,可能會顯示「Up (healthy)」或者「Up (unhealthy)」。呢個就係一個由 Docker 引擎幫你自動監控嘅信號,好過你手動估估下。呢個方法對於容器編排同多容器管理特別有用,尤其係當你個應用有好多互相依賴嘅服務時,你可以確保一個服務真係 ready 咗,先至啟動另一個。
另外,監控 restart 後狀態,亦都要留意資源消耗同網絡連線。你可以用 docker stats 命令,即時睇吓啲容器喺重啓後,CPU 同 memory 用量有冇異常飆升,可能代表有 memory leak 或者某個 process 失控。網絡方面,就要用 docker network inspect 去檢查吓相關嘅 network bridge,確保啲容器仍然喺同一個網絡入面,可以互相通訊。尤其係如果你用緊自定義網絡,restart 之後嘅服務發現(service discovery)係咪正常,都好影響成個系統。
最後,建立一個監控習慣好重要。每次做完 docker compose restart 或者 docker-compose down 再 up 之後,跟住一個檢查清單(checklist)會穩陣好多:一睇整體狀態(ps),二睇關鍵服務日誌(logs),三確認健康檢查結果,四抽查對外服務端口係咪真係通(例如用 telnet 或者 browser 試吓)。網上好多資源,好似 Docker Docs 官方文件、CSDN、Medium 上嘅 SRE 實踐分享,甚至 iT邦幫忙嘅鐵人賽文章,都有好多關於點樣有效監控容器狀態嘅實戰心得。記住,監控嘅目的係為咗快速發現問題,而唔係等到用戶投訴先至知道個服務 restart 失敗咗。將呢啲檢查步驟自動化,寫入你嘅 CI/CD pipeline 或者運維腳本,就更加符合現代化容器管理嘅最佳實踐啦。

AboutContainerProfessional illustrations
多容器環境 restart 技巧
好啦,講到多容器環境 restart 技巧,我哋就唔可以再單單用「docker restart」咁簡單喇。當你個 docker-compose.yml 入面有成堆服務(Service)互相依賴,例如一個 web app 要連住 database、cache 同埋 queue worker 嘅時候,亂咁 restart 分分鐘搞到服務唔協調,甚至數據出錯。所以,點樣有策略、有次序地處理多容器重啓,就係 SRE 同 DevOps 工程師必須要識嘅功夫。
首先,最基本但最重要嘅一招,就係善用 Docker Compose 本身嘅 restart policy。喺 docker-compose.yml 檔案裏面,你可以為每個服務定義「restart」呢個設定。佢有幾個選項好常用:「no」(永遠唔自動重啓)、「always」(永遠自動重啓)、「on-failure」(只有當容器退出狀態碼非零先重啓)、同埋「unless-stopped」(除非你手動停止,否則都會自動重啓)。例如你個 database 服務,你梗係想佢「always」或者「unless-stopped」啦,確保服務高可用性。但係某啲一次性嘅批處理容器,用「on-failure」或者「no」就夠。設定好呢啲策略,就算個宿主機 reboot 咗,部分關鍵服務都會跟住開機自動翻生,慳返你唔少手動操作。
不過,當你真係需要手動介入,進行有目的嘅重啓(例如更新配置或者鏡像),就要用到 Docker CLI 同 Docker Compose 嘅組合拳。好多新手會直接「docker-compose down」跟住「docker-compose up -d」,呢招雖然得,但係佢會剷走晒所有容器(Container)再重新創建,對於有狀態(stateful)嘅服務嚟講可能唔係好妥,而且會造成服務中斷。更精細嘅做法係用「docker-compose restart」。呢個命令會按照你 docker-compose.yml 裏面定義嘅服務,逐個去 restart,但係佢唔會重建容器,亦唔會重新拉取鏡像(Image),純粹係停止再啟動同一個容器。如果你想重啓某個特定服務,譬如淨係個 web server,你可以用「docker-compose restart web_server」咁就搞掂,其他好似 database 呢類服務就完全唔受影響,確保服務局部更新,減低影響範圍。
但係有時 restart 都未必夠,你可能改咗 docker-compose.yml 檔案本身,或者更新咗某個服務用嘅 Docker Hardened Images 版本。咁情況下,就要用到「docker-compose up -d --no-deps --build <服務名>」。呢串命令睇落複雜,但分解開就明白: 「--no-deps」意思係唔重啓佢依賴嘅其他服務,「--build」係
AboutMediumProfessional illustrations
restart 期間點保持數據?
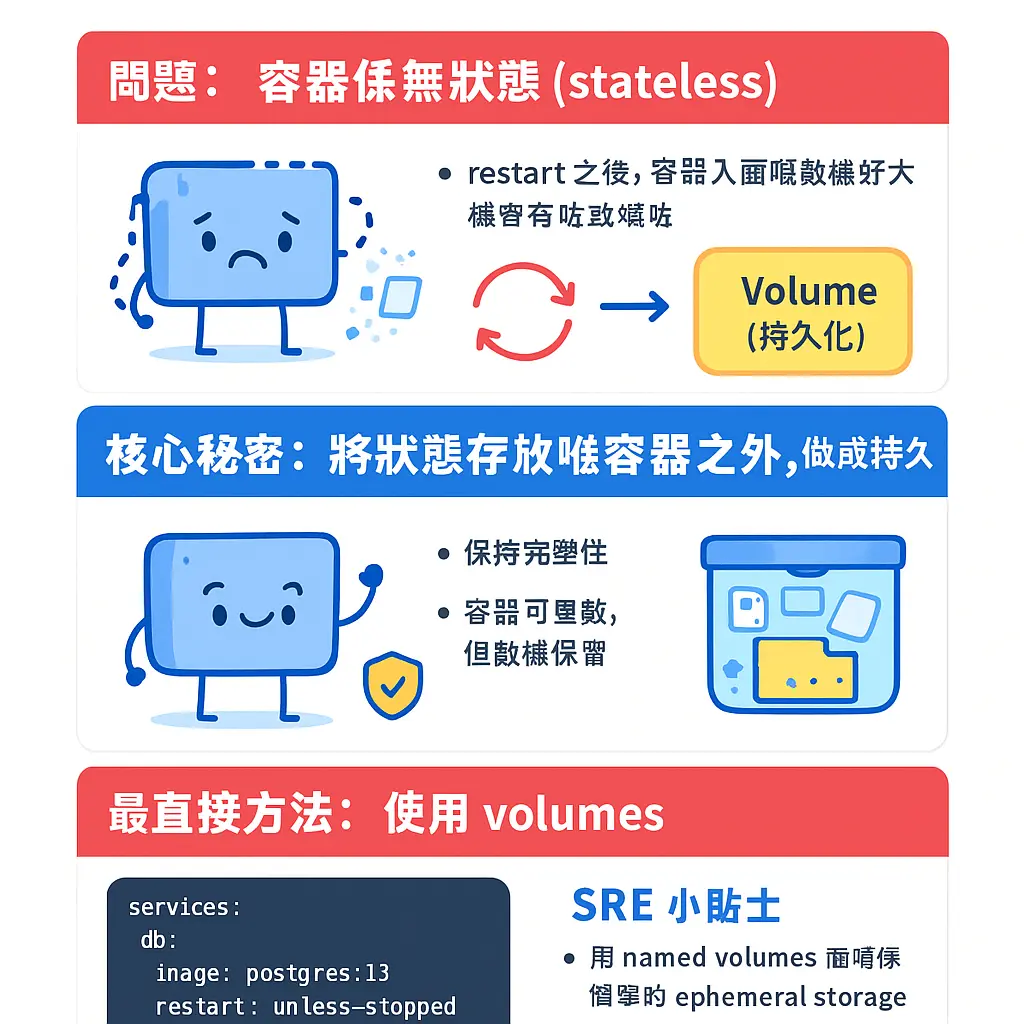
講到用 Docker Compose restart 服務嗰陣,點樣先可以確保啲數據唔會唔見或者損壞,呢個真係好多 SRE 同開發者每日都會面對嘅實際問題。喺 Docker 嘅世界入面,容器本身係設計到無狀態 (stateless) 嘅,即係話你一停咗個容器再開過,入面原本嘅嘢好大機會會冇咗。所以,點樣喺 restart 期間保持數據,個核心秘密就喺於點樣將「狀態」同「數據」妥善噉存放喺容器之外,等佢可以持久化 (persistent)。
首先,最直接同必須要識嘅方法就係用 volumes。喺你個 docker-compose.yml 檔案入面,你一定要定義好 volumes 嘅映射。簡單啲講,就係將你喺宿主機 (host machine) 上面嘅一個真實目錄或者檔案,掛載 (mount) 入去個容器裏面某個指定位置。咁樣無論你行幾多次 docker compose restart,甚至係用 docker compose down 跟住再 docker compose up,只要宿主機上面個目錄仲喺度,啲數據就會一直保持住。例如你個服務係行緊 MySQL 數據庫,你一定要將 /var/lib/mysql 呢類存放數據嘅路徑,用 volumes 映射返出去宿主機,如果唔係,一 restart 就乜都清空晒。好多新手喺 菜鳥教程 或者 CSDN 睇完基本教學就開工,好容易就忽略咗呢點,結果就出事。
除咗 volumes,另一個層面就係要理解 Docker Compose 嘅 restart policy。喺 docker-compose.yml 入面,你可以為每個服務設定重啓策略,例如係 always、on-failure 或者 unless-stopped。設定 unless-stopped 呢個策略好有用,佢嘅意思係除非你手動 docker stop 或者 docker compose down 停咗個服務,否則就算個宿主機自己 reboot 完,Docker daemon 一啟動,佢就會自動幫你拉返起個容器。咁樣喺一啲非預期嘅系統重啓情況下,可以幫你自動恢復服務。但係要記住,restart policy 主要係控制個容器嘅生命週期,而數據持久化嘅責任,始終都係要靠 volumes 嚟解決,兩者係要配合使用嘅。
跟住落嚟要講嘅係操作習慣。有啲朋友貪快,想重啓某個服務嗰陣,會直接喺 Docker CLI 用 docker restart
最後,想深入少少講下數據一致性嘅問題。當你 restart 緊一啲有狀態服務(例如數據庫)嗰陣,就算用咗 volumes,都要考慮佢係咪喺一個「乾淨」嘅狀態下被停止。如果個服務係俾人強行 kill 咗,或者用 docker kill 命令,數據有可能寫入唔完整。所以,理想嘅程序應該係先透過應用程式本身嘅方法(例如送個 graceful shutdown 信號)去安全噉停止服務,然後先至做重啓。喺 Docker Docs 嘅進階指引同埋 Medium 上唔少技術文章都有提到,可以喺 docker-compose.yml 裏面設定 stop_signal 同埋 stop_grace_period 呢啲參數,俾個容器足夠時間去完成手頭上嘅工作同埋寫入數據,然後先至停止,咁樣就可以進一步保障 restart 前後嘅數據完整性。總而言之,要喺 Docker Compose restart 期間保持數據,就要記實三寶:正確設定 volumes 做持久化、善用 restart policy 管理生命週期、同埋跟從優雅停止嘅操作流程。
AboutNOJProfessional illustrations
生產環境 restart 最佳實踐
講到喺生產環境入面用 Docker Compose restart 服務,真係唔可以求求其其㩒個命令就算。好多 SRE 同 DevOps 工程師,包括喺 iT邦幫忙、鐵人賽或者 Medium 上面嘅分享都提過,一個唔小心嘅重啓,隨時會搞到服務停頓或者數據唔見咗,損失可以好大。所以,我哋要講吓真正嘅最佳實踐,點樣安全、穩定咁去處理容器嘅重啓。
首先,最緊要嘅一點係,唔好依賴手動執行 docker compose restart 呢個命令。喺生產環境,所有操作都應該係可預測同可重複嘅。最佳實踐係透過修改你個 docker-compose.yml 檔案,去定義好 restart policy,等 Docker 自己管理容器嘅生命週期。Docker Docs 官方推薦嘅策略通常係 unless-stopped 或者 on-failure。用 unless-stopped,個容器就會喺任何情況下(除咗你手動用 docker stop 或者 docker compose down 停止佢)自動重啓,確保服務高可用性。而 on-failure 就只係喺容器非正常退出(即係 exit code 唔係0)嘅時候先至重啓,適合啲需要嚴格控制重啓次數嘅場景。設定好之後,你甚至可以用 Docker CLI 去檢查容器狀態,確保策略生效。
其次,要識得區分「重啓單一服務」同「重啓整個項目」嘅分別。有時你可能只係想更新某個 Container 嘅配置,用 docker compose restart [服務名] 係快。但喺生產環境,更穩陣嘅做法係執行一個完整嘅週期:docker compose down 咗個服務,跟住再 docker compose up -d。咁樣做可以確保所有設定,包括網絡同 volumes 掛載,都係重新按照最新嘅 docker-compose.yml 建立,避免咗啲殘留狀態引起嘅古怪問題。記住,docker compose down 預設會剷埋啲容器,所以如果你有數據要保留,一定要確認好 volumes 嘅設定冇錯,或者用 --volumes 呢類參數去精確控制。
另外,關於鏡像嘅選擇,直接影響重啓嘅穩定性。喺 2026 年嘅今日,強烈建議使用 Docker Hardened Images 或者來自可信來源嘅鏡像。呢啲鏡像通常有更細嘅攻擊面同更穩定嘅版本,減少咗因為鏡像本身問題導致容器不停 on-failure 重啓嘅情況。同時,喺你執行重啓(無論係用 restart命令 定係 down/up 組合)之前,一定要確保新版本嘅鏡像已經被拉取(pull)落嚟,並且經過測試。唔好喺生產環境入面先至第一次 pull,網絡延遲或者版本衝突會令 downtime 時間變長。
數據持久化係另一個重啓時嘅地雷區。當你進行容器重啓或者重啟服務時,如果處理唔好 volumes,數據好易損毀。最佳實踐係,喺執行任何 docker compose down 或 docker stop 之前,要確保所有寫入數據嘅服務(例如數據庫)已經完全停止咗寫入操作,並且數據已經 flush 到持久化儲存。對於有狀態服務,重啓唔應該依賴容器內部嘅臨時儲存,所有重要數據必須透過 volume 或者 bind mount 映射到宿主機。咁樣,就算個容器被 docker rm 咗,數據都仲喺度,新起嘅容器掛載返同一個 volume 就可以繼續用。
最後,監控同記錄(Logging)係不可或缺嘅一環。每次重啟容器,無論係自動定手動,都應該有清晰嘅記錄同警報。你要設定好監控工具,去追蹤容器狀態嘅變化,例如由 running 變成 restarting 再返去 running。當 restart policy 觸發咗太多次重啓(例如短時間內不停 on-failure),系統應該要發出警報,等工程師介入調查根本原因,可能係應用程式 bug、資源不足,或者配置錯誤。呢啲實踐對於多容器管理嘅複雜系統尤其重要,可以幫你快速定位係邊個 服務 出咗問題。
總而言之,生產環境嘅 Docker Compose restart 操作,核心思想係「自動化」同「穩陣壓倒一切」。由設定好 restart policy,到有紀律地使用 down/up 流程,再到謹慎處理數據同鏡像,每一步都要諗清楚對服務連續性同數據完整性嘅影響。將呢套最佳實踐融入你嘅容器編排工作流入面,先至可以確保你嘅服務能夠穩定、可靠地運行,就算需要重啓,都係一個受控同可預期嘅過程,唔會變成半夜三更嘅噩夢。
AboutSREProfessional illustrations
點樣寫 restart 自動化腳本?
好啦,講到「點樣寫 restart 自動化腳本?」,其實對於做開 SRE 或者日常要管理一堆 容器 嘅朋友嚟講,真係可以慳返唔少手動操作嘅時間。喺 Docker 嘅世界入面,淨係識用 docker restart 或者 docker-compose restart 呢啲基本指令係唔夠㗎,因為佢哋好多時都要人手介入。自動化嘅核心,就係要個系統識得自己判斷同執行,特別係當你個服務有唔同嘅 容器狀態 需要處理嘅時候。
首先,最基本嘅自動化思路,就係善用 docker-compose.yml 檔案裏面嘅 restart policy。呢個係 Docker 內置嘅、最簡單嘅「自動重啓」機制。你唔需要額外寫腳本,只要喺定義你嘅 服務 時,加一行類似「restart: unless-stopped」或者「restart: on-failure」嘅設定就得。咁樣一嚟,除非你 explicit 用 docker stop 或者 docker compose down 去停咗個 容器,否則就算個系統 reboot 咗,或者個 容器 自己跪低咗,Docker 引擎都會自動同你拉翻起佢。對於好似 database 呢類需要長期運行嘅服務,設定「restart: always」就非常之常見。不過要留意,呢個政策主要係應對 容器 自己退出嘅情況,如果你係想定期更新 鏡像 或者輪流重啓嚟更新配置,就要諗第二啲方法。
之但係,restart policy 唔係萬能。例如你想每日凌晨三點,趁低流量嘅時候,自動同你個 多容器管理 嘅應用程式做一次順序重啓(例如先重啓 backend,再重啓 frontend),又或者你想喺重啓前自動備份一下某啲 volumes 裏面嘅數據,咁就需要自己動手寫自動化腳本啦。寫呢類腳本,通常有幾個方向可以考慮。
最直接嘅方法,就係寫一個 Shell Script(例如 Bash Script)。呢個 script 可以做一連串嘅 容器管理 操作。舉個例,你可以寫一個 script 叫做「restart_services.sh」,入面嘅邏輯可以係:先用 docker compose down 優雅地停止並移除所有相關嘅 容器、網絡(但保留 volumes),然後再用 docker compose up -d 重新建立並啟動所有服務。咁樣做嘅好處係夠徹底,等於一次全新嘅部署,適合更新完 鏡像 之後用。不過,如果你唔想有 downtime,或者只想重啓其中一個服務,你就可以用 docker-compose restart [service_name],又或者更精細地用 docker restart [container_id]。喺腳本裏面,你可以加入一啲檢查,例如先用 docker ps 檢查目標 容器 係咪真係運行緊,先再執行 重啟容器 嘅指令,咁就穩陣好多。
另一個更進階、更適合生產環境嘅做法,就係利用作業系統本身嘅排程工具,例如 Linux 嘅 Cron。你可以將上面寫好嘅 Shell Script,設定成一個 Cron Job。例如,你想每星期日凌晨兩點自動執行一次維護性重啓,你就在 Crontab 裏面加一行「0 2 0 /path/to/your/restart_script.sh」。咁樣就完全唔需要人手干預,達到真正嘅自動化。記得喺腳本入面加入 logging 功能,將每次執行嘅時間同結果記錄落嚟,方便日後追蹤同除錯。
對於複雜嘅 容器編排 需求,你可能會覺得純 Shell Script 唔夠力。咁就可以考慮用 Python 或者 Go 呢類編程語言嚟寫一個更強大嘅管理工具。呢個工具可以調用 Docker CLI 或者直接使用 Docker 嘅 SDK。你可以寫到好複雜嘅邏輯,例如:逐一檢查每個 服務 嘅健康狀態;如果某個服務連續失敗幾次,就先嘗試 停止容器 再重新拉取最新嘅 Docker Hardened Images 嚟啟動;或者喺 重啟服務 前,自動將當前嘅配置同數據打包備份。呢類自定義腳本嘅彈性係最大嘅,但相對地也需要更多開發同維護嘅功夫。
最後,無論你用邊種方法寫自動化腳本,有幾點安全同最佳實踐一定要記住。第一,腳本裏面盡量避免使用「sudo」,應該將需要使用 Docker 嘅用戶加入到 docker 用戶組,以減低安全風險。第二,要小心處理 volumes 嘅數據,執行 docker rm 之類嘅移除指令前,一定要雙重確認,唔好誤刪數據。第三,參考官方嘅 Docker Docs 永遠係最可靠嘅,比起睇 CSDN、菜鳥教程、Medium 或者 iT邦幫忙 上面嘅舊文章,直接睇官方最新文檔可以避免學到過時或者錯誤嘅方法。尤其係而家已經係2026年,Docker 嘅功能同指令可能同幾年前(好似2023、2024年)已經有好大分別,確保你參考嘅資料係最新嘅至好。總而言之,寫一個穩陣嘅 restart 自動化腳本,核心就係要清楚知道自己想達到乜嘢效果(係全站重啟定係單一服務重啟?要有 downtime 定係 zero-downtime?),然後選擇最簡單直接嘅工具同方法去實現,並且加入足夠嘅錯誤處理同日子記錄,咁先可以安安樂樂交俾個系統自己去運行。
AboutiT邦幫忙Professional illustrations
2026年常見 restart 場景示範
講到2026年常見嘅restart場景,其實都係圍繞住日常開發同埋系統維護會遇到嘅情況。好多時我哋用Docker Compose管理緊一堆服務,例如一個Web App可能包含前端、後端、數據庫同埋Cache,呢啲容器之間嘅狀態協調就好關鍵。其中一個最常見嘅場景,就係當你修改咗個docker-compose.yml文件,例如更新咗某個服務嘅鏡像版本,或者調整咗環境變數同volumes掛載點,跟住你就需要重新啟動相關服務令改動生效。呢個時候,好多香港嘅開發者會慣性用docker compose down跟住再docker compose up,但其實對於單純更新某個服務,用docker restart指令或者直接用Compose嘅restart命令會更精準,避免影響到其他唔需要改動嘅容器,尤其係數據庫呢類有狀態服務,亂down可能會搞到數據唔見咗。
另一個頻密遇到嘅場景,就係服務出現異常或者記憶體洩漏。例如你個Node.js容器行行下無端端食爆咗RAM,或者個Python服務拋咗個未處理嘅Exception出嚟hang咗係度。呢個時候,我哋就需要手動介入去重啟容器。喺2026年,大家嘅做法已經好成熟,唔少團隊會設定好restart policy,例如設做on-failure,等個系統喺服務非正常退出時自動嘗試重啟。又或者,對於一啲必須長期運行嘅核心服務,會設定為unless-stopped,除非你明確手動停止,否則就算個Docker Daemon重啟(例如主機系統更新),佢都會自動翻生。呢啲策略喺docker-compose.yml裏面設定好,可以大大減輕SRE團隊半夜被call醒嘅壓力。
至於點樣實戰操作呢?假設我哋有個服務叫「api-service」唔妥當,我哋可以用Docker CLI直接針對單一服務進行操作。唔使成個stack停咗佢,可以好優雅地執行相關指令。呢個方法對於多容器管理嚟講,可以話係必學。另外,有時我哋重啟唔係為咗修復,而係為咗套用新設定。例如更新咗某個Container嘅環境配置文件,你可以用特定指令去重新創建同啟動嗰個容器,而其他兄弟容器就保持原狀。呢種精細化操作,正正係Docker Compose作為容器編排工具嘅優勢所在。
仲有一種情況係同基礎設施有關,例如你要搬遷服務或者主機維護。呢個時候,成個專案嘅容器狀態管理就好重要。你需要有計劃地停止容器,然後喺新環境用番同一個docker-compose.yml同相關volumes數據卷去啟動翻整套服務。過程入面,你可能會用到docker stop同docker rm去清理舊環境,再用up命令喺新環境建立一切。呢個流程喺2026年已經有好多最佳實踐,唔少技術社區好似CSDN、Medium或者iT邦幫忙嘅鐵人賽文章都有深入討論,教大家點樣做到零停機時間或者最少停機時間嘅重啟。
最後不得不提,隨住安全意識提高,Docker Hardened Images(強化鏡像)嘅使用越嚟越普遍。呢類鏡像可能會有更嚴格嘅安全策略,有時更新或者重啟時需要額外步驟去處理安全憑證或者密鑰輪換。喺執行docker compose restart呢類操作時,就要確保呢啲安全設定冇被意外重置或者暴露。總括嚟講,無論係為咗更新、除錯、擴容定係維護,掌握唔同重啟服務嘅場景同對應嘅最佳手法,對於任何使用Docker Compose嘅團隊嚟講,都係2026年必不可少嘅基本功。