AboutDockerProfessional illustrations
Docker Swarm Init 入門指南
好啦,各位想玩轉容器集羣嘅朋友,今次我哋就深入淺出講下 Docker Swarm Init 呢個入門必經步驟。簡單嚟講,Docker Swarm 就係 Docker 自家出嘅容器編排工具,唔使好似 Kubernetes 咁複雜,用返你熟嘅 Docker CLI 就可以輕鬆管理一個分散式系統。而 docker swarm init 呢個指令,就係你將一部裝咗 Docker Engine 嘅主機(通常係你手頭上最勁嗰部 Linux 機),初始化成為整個 Swarm 集羣嘅「大佬」——即係 Manager Node(管理節點)嘅關鍵動作。喺 2026 年嘅今日,Swarm 依然係中小型項目做容器編排、實現服務高可用同負載均衡嘅一個又快又靚嘅選擇。
咁點解要初始化一個 Swarm 呢?其實就係為咗開啟 swarm mode。當你喺終端機打落 docker swarm init 呢句咒語,你腳下呢部主機嘅身份即刻升格,唔再係一部孤獨嘅 Docker 主機,而係成個容器集羣嘅指揮中心。背後,Docker 會幫你建立一套基於 Raft consensus(Raft 共識算法)嘅管理架構,呢個算法就係確保幾個 Manager Node 之間數據一致、唔會「撞鬼」嘅核心。初始化成功後,系統會自動生成兩組重要嘅 安全密鑰:一組係俾其他主機加入做 Manager Node 用,另一組就係加入做 Worker Node(工作節點)用。記住呢點好重要,因為你之後擴展集羣,就係靠呢啲 token 嚟做身份驗證,呢個就係 Swarm 嘅 證書管理 基礎。
做初始化嗰陣,通常要諗清楚網絡點樣設定。默認情況下,docker swarm init 會自動為個集羣創建一個 覆蓋網絡,等唔同主機上嘅容器可以互相通訊。但如果你部主機有多過一個網絡接口(例如有內網 IP 同公網 IP),你就需要用 --advertise-addr 參數去指定用邊個 IP 地址嚟同其他節點「打招呼」。例如你打算用內網 IP 192.168.1.100 做管理通訊,咁指令就係 docker swarm init --advertise-addr 192.168.1.100。呢個設定直接影響到之後 節點管理 同 網絡配置 嘅穩定性,搞錯咗可能會令到啲節點失聯。
初始化完成之後,你嘅 Docker CLI 就會多咗一堆以 docker service 開頭嘅新指令,呢啲就係 Docker Service 嘅核心。同你以前用開、只喺單機行嘅 docker run 唔同,Docker 服務 係一個集羣層面嘅概念。你可以用 docker service create 去部署一個服務,並且指定要開幾多個 服務副本,Swarm 就會自動幫你喺唔同嘅 工作節點 上面分派同管理呢啲容器,實現 多容器部署 同自動 負載均衡。呢個就係 容器編排 嘅魔力,你唔使再逐部機 SSH 入去搞。
對於習慣用 docker-compose 寫 YAML配置 嘅朋友,Swarm 一樣有好消息。你嗰份 docker-compose.yml 檔案,只需要升級少少語法,就可以用 docker stack deploy 呢個指令,直接成個 Docker Stack 部署上 Swarm 集羣。Stack 可以理解為一組互相關聯嘅 Service,例如一個網站可能有 web server、database、cache 幾個服務,用 Stack 就可以一次過管哂,非常方便。呢個方法將你本地開發用 docker-compose 嘅體驗,無縫延伸到生產環境嘅 集羣管理,減低學習成本。
最後提多個實用貼士,就係點樣睇返個集羣嘅狀態同加入指令。初始化完,記得立即用 docker node ls 睇下,你會見到目前集羣只有自己一個節點,狀態係「Ready」同角色係「Leader」。另外,系統初始化時輸出嗰句 docker swarm join-token 指令,你一定要抄低,或者之後隨時用 docker swarm join-token worker 或 docker swarm join-token manager 睇返。呢個就係你邀請新主機加入,進行 集羣初始化 擴展嘅門票。記住,一個生產環境嘅 Swarm 集羣,最好有奇數個(例如3個或5個)Manager Node 嚟維持 Raft 算法嘅高可用性,其他就全部可以設為 Worker Node 專心跑容器。
AboutDockerProfessional illustrations
初始化 Swarm 集羣步驟
好啦,咁我哋就直入正題,講下點樣初始化 Swarm 集羣。呢個步驟係建立你成個容器編排系統嘅地基,做得好,後面嘅服務部署同節點管理就會順好多。首先,你要確定邊部機做管理節點 (Manager Node)。通常呢,你會揀一部最穩定、資源足夠嘅 Linux 伺服器,然後用 Docker CLI 喺上面打一句好簡單但又好關鍵嘅指令:docker swarm init。呢句指令一執行,你部機嘅 Docker Engine 就會即刻啟動 swarm mode,自動成為成個 Swarm 集羣嘅第一個同埋唯一一個 Manager Node。
執行完之後,CLI 會彈幾行重要資訊出嚟,你一定要抄低佢。最重要嗰行就係加入集羣用嘅 安全密鑰 (security tokens),分為 worker node 同 manager node 兩種。呢個 token 就好似你公司嘅門禁卡一樣,其他機要靠佢先可以加入你個 Swarm 集羣。如果你唔小心唔見咗,都可以用 docker swarm join-token 指令重新生成,但最好一開始就妥善保存。另外,佢仲會顯示返你部 Manager Node 嘅 IP 地址同端口,其他節點就要透過呢個地址嚟連接。
跟住落嚟,就要處理網絡配置。當你初始化 Swarm 嗰陣,系統會自動幫你建立一個 覆蓋網絡 (overlay network),專畀 Swarm 內部嘅 Docker服務 互相通訊用,呢個網絡係跨主機嘅,即係話唔同 工作節點 上面嘅容器都可以直接傾偈,對於多容器部署嘅複雜應用嚟講係必須嘅。當然,你亦可以之後按需要自定義更多嘅 overlay network,去分隔唔同服務或者環境。
講到管理節點,不得不提背後嘅 Raft 共識算法 (Raft consensus)。當你初始化咗第一個 Manager Node,佢就已經行緊 Raft 嚟管理集羣狀態。為咗高可用性,你之後最好加多兩個 Manager Node,等集羣有個奇數數量(例如1、3、5)嘅管理節點。咁樣就算其中一部機跪低,其他 Manager Node 都可以透過 Raft 協議保持共識,成個集羣管理同服務編排嘅決策依然可以繼續運作,唔會停擺。呢個就係點解生產環境唔建議只得一個 Manager Node 嘅原因。
初始化完成,個 Swarm 集羣仲係得個殼,要真正發揮容器編排嘅威力,就要開始部署服務。呢度你可以直接用 docker service create 指令去逐個服務部署,但更專業、更可管理嘅做法,就係用 Docker Stack。Docker Stack 係透過一個 YAML配置 檔案(通常就係 docker-compose.yml 嘅升級版)嚟定義成個應用堆棧,裏面可以包含多個 Docker Service、網絡同埋 Volume 配置。然後用一句 docker stack deploy -c your-compose-file.yml your_stack_name,就可以將成個應用連同佢需要嘅服務副本數量、網絡配置、端口映射等一次過部署到個集羣度,非常方便,亦方便版本控制。
最後要提提,初始化之前嘅準備功夫都好重要。確保所有將會加入做 worker node 或者 manager node 嘅機器,佢哋嘅 Docker Engine 版本都係兼容嘅,最好用最新穩定版,避免因為版本差異引起古怪問題。另外,防火牆規則一定要開返 Swarm 管理用嘅端口(默認係 TCP 2377)、節點通訊端口(TCP/UDP 7946)同埋 覆蓋網絡 用嘅端口(UDP 4789)。如果唔係,啲節點會連唔到,或者服務網絡唔通,咁就白做功夫啦。總括嚟講,初始化 Swarm 集羣 係將多部獨立主機變成一個協同工作嘅分散式系統嘅第一步,步驟本身唔複雜,但每一步背後嘅設定同理解,就決定咗你個容器集羣嘅穩定性同擴展性。
AboutDockerProfessional illustrations
設定管理節點 (Manager Node)
好啦,講完點解要建立Swarm,我哋而家就直入正題,講下點樣設定管理節點 (Manager Node)。呢一步係用Docker Swarm建立容器集羣嘅第一步,亦係最關鍵嘅一步,因為你係喺呢部主機上面,用Docker CLI發出 docker swarm init 呢個指令,正式啟動 swarm mode。簡單嚟講,你就係將呢部主機「升呢」做成個集羣嘅「大佬」,亦即係 Manager Node。佢唔單止會負責管理同編排成個集羣,仲會用 Raft consensus 演算法嚟維持自己同其他管理節點之間嘅狀態一致性,確保成個分散式系統嘅高可用性。
咁點樣開始呢?假設你已經有一部裝好最新版 Docker Engine 嘅 Linux 主機(例如Ubuntu 22.04或者更新),你只需要打開終端機,用一個好簡單嘅指令就得。不過,喺執行之前,有啲準備功夫要做吓。首先,你要確保部主機嘅hostname同IP地址(尤其係對內嗰個,例如192.168.1.100)係設定好嘅,因為其他節點要靠呢個地址加入嚟。跟住,你要諗吓用邊個網絡介面卡嚟做集羣通訊,特別係如果你部機有多個IP(例如有內網同公網)嘅話。通常呢,最穩陣係指定內網IP,咁樣集羣內部嘅溝通(例如Raft同步、服務發現)就會又快又安全。
準備好之後,你就可以輸入核心指令嘞。最基本嘅做法就係直接打 docker swarm init。不過,我強烈建議你加多個參數 --advertise-addr 去明確指定用邊個IP地址做通告,例如 docker swarm init --advertise-addr 192.168.1.100。點解要咁做?因為如果你唔指定,Docker可能會自動揀一個,有時會揀錯咗去localhost或者另一個唔對外嘅網絡卡,咁樣其他工作節點 (Worker Node) 就會連唔到你呢個管理節點,成個集羣初始化就失敗啦。所以,明確指定IP係一個好習慣,可以避免好多無謂嘅麻煩。
當你成功執行指令之後,Docker Engine就會做一連串嘅幕後功夫。首先,佢會將部主機切換到 swarm mode。跟住,佢會自動生成兩類好重要嘅 安全密鑰 (security tokens):一個係俾工作節點加入集羣用嘅,另一個係俾其他管理節點加入用嘅(用嚟做高可用性設定)。另外,佢會為成個Swarm集羣建立一套證書管理體系,包括根證書同節點證書,用嚟加密節點之間嘅通訊,確保網絡配置同管理指令嘅傳送係安全嘅。同時,佢會建立一個預設嘅 覆蓋網絡 (overlay network),名叫 ingress,呢個網絡好重要,佢會自動幫你做負載均衡同端口映射,等你之後部署嘅Docker服務可以喺唔同節點之間互通,仲可以俾外界訪問到。
成功之後,CLI會顯示一段成功訊息,最重要係會顯示一條好似 docker swarm join --token SWMTKN-1-xxxxx 192.168.1.100:2377 嘅指令。呢條就係工作節點加入集羣嘅「入場券」啦,你一定要記低或者抄低佢,因為其他節點就係靠呢條指令加入你個Swarm。如果你唔小心唔見咗,都唔使驚,你可以隨時喺管理節點上用 docker swarm join-token worker 呢個指令,重新顯示返條加入指令同個token。
設定好單一個管理節點之後,雖然已經可以運作,但對於生產環境嚟講,單點故障風險太高。所以,我哋通常會建議你設定多個管理節點,組成一個管理節點集羣(通常係3個或者5個,奇數個數係為咗方便 Raft consensus 演算法做決策)。點樣加多啲管理節點呢?方法同加工作節點差唔多,只係你要喺第一台管理節點上,用 docker swarm join-token manager 拎到管理員專用嘅token同指令,然後喺第二部、第三部主機上面執行。咁樣,呢幾部管理節點就會透過Raft協議保持同步,就算其中一部機死咗,其他管理節點都可以繼續維持成個容器編排系統嘅運作,真正做到高可用性。
最後提多一個實用技巧。好多時我哋唔係直接喺主機上操作,或者想將設定自動化。你可以考慮用 docker-machine(雖然佢嘅熱潮有啲過咗,但喺某啲場景仲有用)或者直接用雲供應商嘅SDK去初始化主機。另外,當你個Swarm集羣設定好之後,你之後部署應用,好多時會用 Docker Stack 同 docker-compose 嘅YAML檔案格式嚟做多容器部署。呢啲YAML檔案可以好清晰咁定義你嘅Docker服務、服務副本數量、網絡配置同資源限制,然後用一個 docker stack deploy 指令就搞掂晒,非常方便管理。記住,所有呢啲高階操作,都係建基於你最初成功設定好呢個管理節點嘅基礎之上,所以第一步一定要做得穩陣。
AboutWorkerProfessional illustrations
配置集羣網絡設定
好啦,講完點樣用 Docker CLI 嘅 docker swarm init 去啟動個 Swarm,同埋點樣加入 worker node 之後,我哋就要深入啲,講下點樣「配置集羣網絡設定」。呢個步驟好關鍵,因為網絡設定直接影響到你個 容器集羣 入面,啲 Docker 服務 之間可唔可以順利溝通,同埋外界點樣訪問到你嘅服務。喺 Swarm mode 底下,網絡唔再係單機咁簡單,而係要考慮到跨主機、服務副本 之間嘅連通性同埋負載均衡。
首先你一定要明,當你初始化一個 Swarm 嗰陣,Docker Engine 已經自動幫你創建咗兩個默認網絡。第一個係「ingress」網絡,呢個就係負責負載均衡同端口映射嘅關鍵。當你發佈一個服務端口(例如 -p 8080:80),所有加入咗 Swarm 嘅節點(無論係 manager node 定係 worker node)都會監聽嗰個端口(例子中嘅8080)。然後 ingress 網絡就會用一種叫「routing mesh」嘅技術,將外來嘅請求,智能地路由到任何一個運行緊該服務容器嘅節點上,完全唔使你自己煩點樣做負載均衡,好方便。第二個默認網絡係「docker_gwbridge」,佢主要係負責將你個別嘅容器連接到宿主機嘅外部網絡,等容器可以上到網。不過,呢兩個默認網絡未必夠用,尤其係當你想隔離唔同 Docker Stack 或者服務之間嘅通訊時,你就需要自己創建覆蓋網絡。
咁點樣自定義網絡呢?呢度就用到 Docker CLI 嘅 docker network create 命令啦。最重要係要加 --driver overlay 呢個參數,因為只有 Overlay 類型嘅網絡,先可以跨越唔同嘅主機,令到唔同節點上嘅容器都可以好似喺同一個局域網入面咁直接通訊。例如,你可以創建一個專屬你個應用嘅網絡:docker network create --driver overlay --subnet 10.0.9.0/24 my_app_net。創建好之後,當你透過 docker service create 或者用 docker-compose 嘅 YAML 配置去部署服務時,就可以指定個服務連接到呢個自定義嘅 my_app_net。咁樣做有咩好處?第一,安全隔離:唔同 Stack(例如一個 WordPress Stack 同一個後端 API Stack)可以用唔同嘅 Overlay 網絡,佢哋之間預設係唔通嘅,減低咗橫向移動嘅風險。第二,服務發現:連接到同一個 Overlay 網絡嘅服務,可以直接用服務名稱當作主機名嚟互相訪問,呢個係 Docker 內置嘅 DNS 功能,對於多容器部署同微服務架構嚟講,簡直係必需品。
講到網絡配置,仲有一個實用設定就係點樣將服務「釘死」喺某個特定節點運行,並且用「host」網絡模式。呢個通常用喺一啲對網絡性能要求極高,或者需要直接使用宿主機特定端口(而唔係用 routing mesh)嘅情況。例如,你有一個監控服務需要直接讀取宿主機嘅網絡數據,你就可以喺 docker service create 時加上 --network host 同埋 --mode global 或者用放置約束(placement constraint)將服務鎖定喺特定標籤嘅節點。不過要留意,用 host 模式會令到服務失去咗 Swarm 提供嘅一層網絡隔離同靈活性,所以要小心使用。
最後,安全都係網絡設定不可忽視嘅一環。喺 Swarm 入面,所有管理通訊(即係 Manager Node 之間為咗維持 Raft consensus 而作嘅溝通)同埋覆蓋網絡嘅數據,預設都已經係加密嘅。但係如果你有更高嘅安全要求,你可以喺創建 Overlay 網絡時加入 --opt encrypted 參數,咁樣連容器之間嘅數據傳輸都會被加密。雖然會帶來少少性能開銷,但對於喺公共雲或者唔信任嘅網絡環境下運行分散式系統,呢個選項就非常之有用。另外,記得定期輪換你個 Swarm 用嚟加密同解密嘅安全密鑰,呢啲都可以透過 Docker CLI 嘅相關命令去管理,確保你個集羣嘅通訊安全唔會因為時間太長而出現漏洞。
總括嚟講,配置 Swarm 嘅集羣網絡設定,唔單止係創建個網絡咁簡單,而係要根據你應用程式嘅架構、安全要求同埋性能需求,去規劃點樣運用 ingress 網絡、自定義 Overlay 網絡,甚至係 host 網絡。一個規劃得宜嘅網絡層,可以令到你之後用 Docker Stack 透過 YAML配置 去部署複雜應用時,更加得心應手,亦都係確保你個容器編排環境穩定同高效嘅基石。記住,所有呢啲設定,無論係用命令定係寫入 docker-compose.yml 檔案,都係為咗令到你個分散式系統更加可靠同易於管理。

AboutManagerProfessional illustrations
使用 --advertise-addr 參數
好啦,講到點樣用 docker swarm init 去建立一個 Swarm 集羣,其中一個好關鍵但又好易被忽略嘅參數就係 --advertise-addr。呢個參數係乜嘢嚟?簡單啲講,佢就係你部機(特別係 Manager Node)用嚟「自我介紹」俾集羣入面其他 Worker Node 聽嘅地址。當你喺部主機度執行 docker swarm init 嗰陣,如果你部機有多過一張網絡卡(例如一張係內聯網用,一張係上網用),又或者有多個 IP 地址,Docker Engine 未必會自動揀啱嗰個 IP 去同其他節點溝通。咁樣就會搞到其他節點搵唔到你個 Manager Node,成個 容器集羣 嘅初始化(cluster initialization)就會失敗,或者之後啲 工作節點 加入唔到。
點解呢個參數咁重要?因為 Docker Swarm 嘅運作核心係建基於 Raft consensus 算法。所有嘅 管理節點 都要透過呢個廣告地址(advertise address)去互相溝通,同步狀態,確保成個 分散式系統 嘅數據一致。如果你冇設定好,可能你喺本機測試冇問題,但其他機就完全連唔到你個 Swarm,咁就做唔到真正嘅 節點管理 同 容器編排 啦。
舉個實際例子,假設你部 Linux 伺服器有兩個 IP:一個係內部私有 IP 192.168.1.100,另一個係公有雲供應商派嘅 IP 10.0.0.5。你個團隊其他同事嘅伺服器都喺同一個內聯網 192.168.1.0/24 入面。如果你就咁打 docker swarm init,Docker CLI 可能自動揀咗個公有 IP 10.0.0.5 做廣告地址。咁當你叫同事喺另一部機用 docker swarm join 加入做 worker node 時,佢哋就會嘗試去連 10.0.0.5 呢個地址,但呢個地址喺內聯網根本唔通,結果就係加入失敗。正確做法應該係明確指定內聯網 IP:docker swarm init --advertise-addr 192.168.1.100。咁樣,其他節點收到嘅加入指令就會包含正確嘅內聯網地址,順利完成 集羣初始化。
除咗確保網絡連通,--advertise-addr 仲關乎 安全密鑰 同 證書管理。當你初始化 Swarm 嗰陣,Docker Engine 會自動生成一整套 TLS 證書同加密金鑰,用嚟確保節點之間嘅通訊安全。呢啲安全資訊會同你設定嘅廣告地址綁定。如果之後你亂改部機嘅 IP 或者一開始就設定錯,可能會導致證書驗證失敗,令到節點被踢出集羣,影響 服務部署 同 多容器部署 嘅穩定性。
對於進階嘅 集羣管理 場景,例如你想分開管理流量同數據同步流量,呢個參數就更加關鍵。有啲大型部署會將 管理節點 之間用於 Raft 同步嘅流量,同埋 Docker服務 之間用於 負載均衡 同 服務副本 通訊嘅流量,行唔同嘅網絡介面。咁樣可以提升安全性同效能。喺呢種情況下,你就要好小心咁規劃同設定 --advertise-addr,確保管理流量行專用網絡。同時,你亦可以配合 --listen-addr 參數(雖然預設同廣告地址一樣)去微調節點監聽連接嘅介面,構建更穩健嘅 網絡配置。
另外,當你之後用 Docker Stack 透過 YAML配置 檔去部署一堆相關服務,或者用 docker-compose 檔去配合 Swarm 模式做部署時,底層個 Swarm 集羣嘅網絡健康係一切嘅基礎。如果管理節點嘅廣告地址設定不當,導致 覆蓋網絡(Overlay Network)建立唔到,咁你喺 Stack 檔裡面設定嘅 端口映射 同服務間通訊都會出問題。所以,喺最初執行 docker swarm init 嗰一刻,花多少少時間確認個 --advertise-addr 設定,絕對係省卻日後大量麻煩嘅明智之舉。
總括嚟講,--advertise-addr 參數雖然只係 docker swarm init 命令嘅一個選項,但佢直接影響到成個 Docker Swarm 集羣嘅誕生同埋長期健康。無論你係喺本地用 docker-machine 建立虛擬機嚟玩,定係喺生產環境部署真實嘅 Linux 伺服器,都應該養成習慣,檢查清楚主機嘅網絡介面,並明確指定一個集羣內所有節點都能穩定訪問到嘅 IP 地址作為廣告地址。呢個步驟係成功實踐 容器編排 同構建可靠 分散式系統 不可或缺嘅一環。
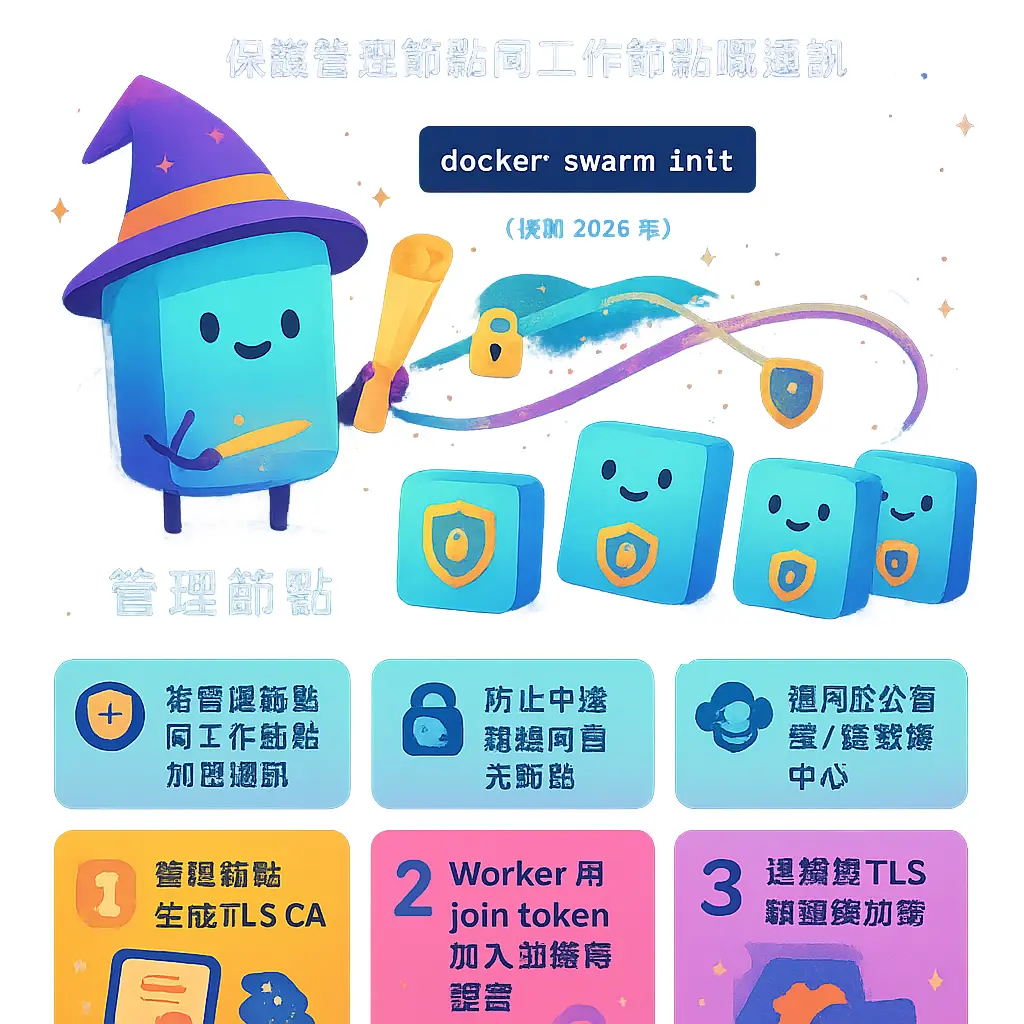
AboutworkerProfessional illustrations
設定集羣 TLS 證書
好,而家我哋就深入講下點樣設定集羣 TLS 證書。喺 Docker Swarm 嘅世界入面,TLS(Transport Layer Security)證書係保安嘅基石,尤其係當你個容器集羣要處理敏感資料,或者喺唔完全信任嘅網絡環境(例如公有雲或者跨數據中心)入面運行嘅時候。簡單啲講,TLS 證書就係用嚟加密管理節點同工作節點之間嘅通訊,確保冇人能夠中途竊聽或者冒充其他節點加入你個 Swarm,搞亂晒你個分散式系統。
點解 TLS 證書咁重要?想像下,你喺 2026 年用 Docker CLI 初始化一個 Swarm,當你行 docker swarm init 嗰陣,Docker Engine 其實已經自動幫你生成咗一套用嚟內部通訊嘅 TLS 證書。呢套證書確保咗所有喺 swarm mode 下嘅節點(包括你之後用 docker swarm join 加入嘅 worker node 同其他 manager node)之間嘅對話,都係經過加密同驗證。呢個過程同 Raft consensus 演算法嘅運作息息相關,因為 Raft 需要節點之間頻繁交換訊息嚟達成一致,如果呢啲訊息被篡改,成個集羣管理同狀態都會出問題。所以,設定 TLS 唔係一個「可選」嘅進階功能,而係構建安全容器編排環境嘅基本步。
咁實際操作上,我哋可以點樣管理同設定呢啲證書呢?首先你要明白,Docker Swarm 嘅 TLS 涉及幾種唔同嘅證書同密鑰:根證書、管理節點證書同工作節點證書。預設情況下,當你初始化集羣,Docker 會幫你打理晒,所有證書預設有效期係 90 日,並且會自動輪換。但係,對於一啲對保安有更高要求,或者需要符合特定公司政策(例如要用自己內部嘅證書頒發機構)嘅團隊,你就需要進行自訂設定。你可以透過修改 Docker daemon 嘅設定檔(通常喺 Linux 系統上係 /etc/docker/daemon.json),指定用自己提供嘅根 CA 證書同密鑰。呢個做法俾你完全掌控證書嘅簽發同生命週期管理,對於大型企業或者需要長時間運行嘅服務部署嚟講,尤其關鍵。
舉個具體例子,假設你公司有內部 PKI,你可以用自己嘅 CA 嚟簽發 Swarm 需要嘅證書。步驟大概係:首先,你要準備好你嘅 CA 證書同私鑰;然後,喺初始化 Swarm 或者加入節點之前,喺每個節點嘅 Docker Engine 設定入面,指向呢啲自訂嘅證書路徑。咁樣做嘅好處係,所有節點之間嘅信任關係都建立喺你公司內部嘅 CA 之上,而唔係依賴 Docker 自動生成嗰啲。萬一有節點離線或者新節點加入,證書嘅驗證過程都會更加清晰同受控。當然,呢個過程涉及較多關於網絡配置同安全密鑰管理嘅知識,建議喺測試環境充分驗證先至放上生產環境。
另外,有一點好容易被忽略但好重要嘅,就係證書輪換。喺 2026 年,保安最佳實踐都強調定期輪換密鑰同證書。Docker Swarm 本身有自動輪換機制,但如果你用緊自訂證書,就要自己建立一套輪換流程。例如,當你嘅服務證書就快到期,你需要喺唔影響現有 Docker 服務同 Docker Stack 運行嘅情況下,逐步更新每個節點上嘅證書。一個常見做法係,逐個節點進行更新:先將一個工作節點排空(drain)任務,更新其證書設定後重啟 Docker Engine,再將佢重新加入集羣參與工作。對於管理節點,就要更加小心,因為佢哋負責 Raft 共識,最好逐個進行,確保集羣嘅高可用性唔會受影響。呢個過程正正體現咗節點管理同集羣管理嘅細緻功夫。
最後,我想提下 TLS 證書同其他 Swarm 功能嘅協同。例如,當你透過 Docker Stack 用 YAML配置 檔案部署一組多容器服務時,服務之間嘅通訊可能會用覆蓋網絡。呢啲虛擬網絡本身已經有加密,但節點間嘅控制層面通訊(即係管理節點下達指令俾工作節點)就係靠我哋上面講嘅 TLS 證書嚟保護。又例如,當你設定服務副本同負載均衡時,背後嘅健康檢查同狀態更新訊息,都係喺 TLS 加密嘅通道入面傳送。所以,妥善設定 TLS 證書,唔單止係為咗「加密」,更加係為咗確保整個容器編排系統嘅完整性、可靠性同可信任性,令到你嘅分散式應用可以安心咁喺容器集羣入面運行。記住,保安唔係一個功能,而係一個過程,定期檢視同更新你嘅 TLS 設定,應該成為你維護 Swarm 集羣嘅常規工作之一。
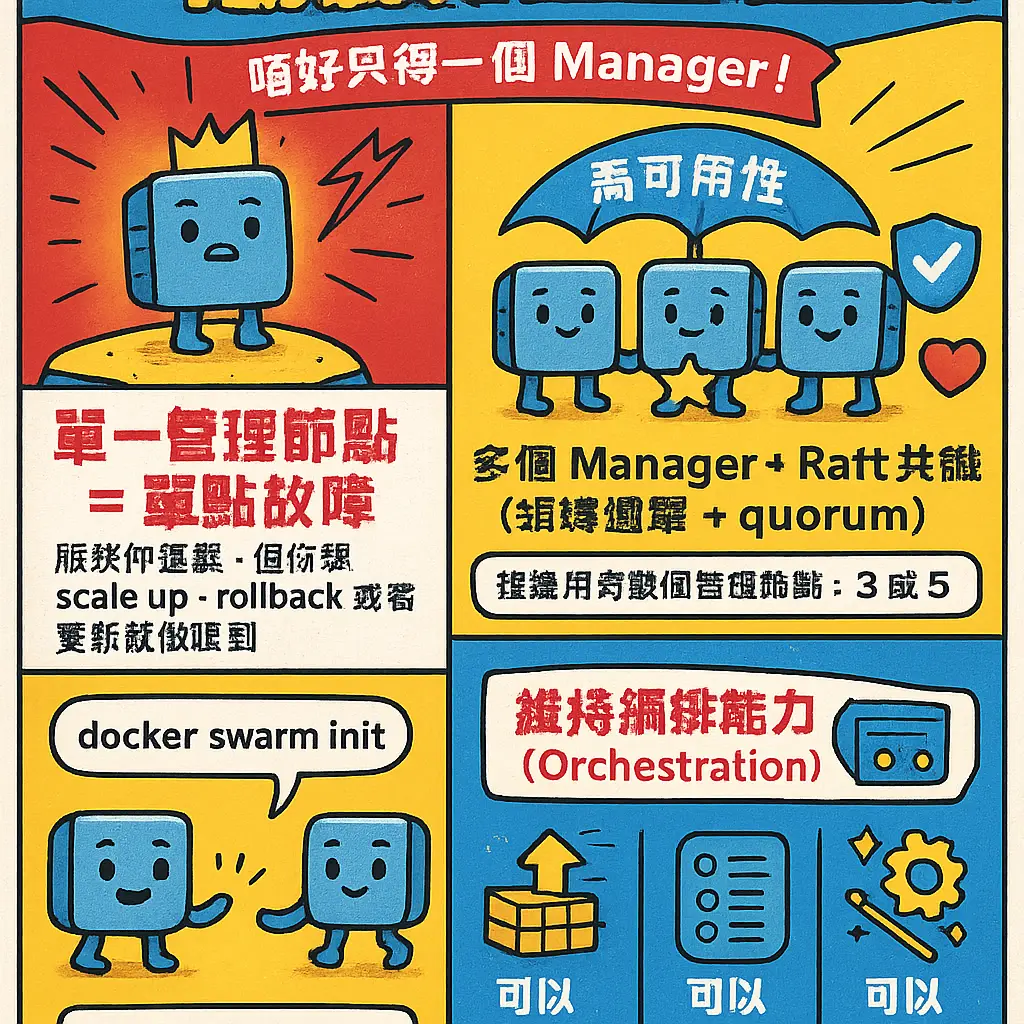
AboutmanagerProfessional illustrations
管理節點高可用性配置
講到 Docker Swarm 嘅管理節點高可用性配置,呢個真係維繫成個容器集羣命脈嘅核心課題。好多 DevOps 團隊初初玩 Swarm,以為起咗個 manager node 就一勞永逸,但實情係,如果只得一個管理節點,佢一死機,成個集羣嘅編排能力(即係 container orchestration)就會即刻癱瘓,啲服務雖然仲行緊,但你想 scale up、rollback 或者更新配置就完全冇可能。所以,高可用性(High Availability) 嘅設定,就係要確保管理平面(management plane)永遠有後備,唔會因為單點故障而停擺。
點樣做到呢?關鍵在於 Swarm 內置嘅 Raft 共識算法(Raft consensus)。當你初始化 Swarm(即係用 docker swarm init)嗰陣,你建立嘅第一個節點就係管理節點,同時亦都係 Raft 數據庫嘅起點。呢個數據庫會記低晒成個集羣嘅狀態,包括所有服務(Docker Service)、網絡配置(network configuration)、同埋密鑰等等。要實現高可用,你就要加多幾個管理節點落去,形成一個奇數數量(例如 3、5、7 個)嘅管理節點羣組。點解要奇數?因為 Raft 算法要過半數節點同意先可以達成共識,奇數可以避免投票打成平手。通常生產環境會用 3 個管理節點,呢個係平衡資源同可靠性嘅甜點。
具體點樣加管理節點呢?好簡單,喺第一台管理節度用 docker swarm join-token manager 拎返條安全密鑰(security token),然後喺其他準備好嘅 Linux 伺服器上,安裝好 Docker Engine,行返條 join 命令就得。加入之後,呢啲管理節點就會自動同步 Raft 數據庫嘅狀態。你要記住一點,所有管理節點喺理論上係平等嘅,你喺任何一個 manager node 度用 Docker CLI 落命令(例如管理 Docker Stack 或者服務),佢都會透過 Raft 算法將變更同步到整個管理節點羣組。不過,為咗減輕負擔,你可以將一啲純粹做運算嘅工作,指派去 worker node,等管理節點專心做編排同維持集羣狀態。
管理節點嘅高可用配置,亦都牽涉到網絡同安全。首先,所有管理節點之間必須有穩定、低延遲嘅網絡連線,因為佢哋要不斷通訊來維持共識。如果網絡分區(network partition)太耐,可能會導致集羣分裂。其次,Swarm 會自動管理一整套 TLS 證書,用嚟加密節點間嘅通訊同驗證身份,呢個就係所謂嘅證書管理。你作為管理員,要定期留意證書有冇過期,雖然 Docker 有自動輪換機制,但了解原理先可以喺出問題時識得排查。
另外,規劃管理節點嘅硬件同部署位置都好重要。雖然管理節點唔使跑你嘅業務容器,但佢要處理 Raft 同步同集羣指令,所以需要穩定嘅 CPU、記憶體,同埋最重要係可靠嘅磁碟 I/O,因為 Raft 日誌要寫入磁碟。建議將呢幾個管理節點分散喺唔同嘅實體機架、甚至唔同嘅可用區(如果係雲環境),避免一個機櫃斷電就一鑊熟。同時,你要設定好監控,留意管理節點嘅系統負載同 Raft 領導者(leader)狀態,通常你可以用 docker node ls 嚟睇吓節點嘅狀態同角色。
最後,要提一提故障應對。假設你有一個 3 管理節點嘅集羣,死咗一個,集羣依然可以正常運作,因為仲有兩個可以達成共識。呢個時候,你要盡快修復或者替換死咗嗰個節點。步驟通常係:喺故障節點上移除 Swarm 成員身份(如果部機仲 access 得到),然後喺一部新機上用 manager token 加入,成為新嘅管理節點。如果死嘅係 Raft leader,Swarm 會自動重新選舉,過程對運行緊嘅容器服務應該係透明嘅,但期間短暫嘅管理命令延遲係有可能嘅。記住,千萬唔好將所有管理節點一次過重啟,咁樣可能會令 Raft 集羣冇咗過半數成員而完全停擺。總而言之,管理節點嘅高可用性唔係「設完就算」,而係一個涉及規劃、部署、監控同維護嘅持續過程,係你 Docker Swarm 容器編排平台穩陣嘅基石。

AboutSwarmProfessional illustrations
加入工作節點 (Worker Node)
好啦,講完點樣初始化個 Docker Swarm 同埋點樣設定 Manager Node,咁下一步梗係要將其他主機加埋入嚟做 Worker Node 啦。呢個步驟就係真正擴展你個 容器集羣 嘅關鍵,令到你嘅 Docker 服務 可以喺多部機上面運行,做到 負載均衡 同高可用性。簡單啲講,Worker Node 就係集羣裏面嘅「勞動力」,專門負責執行由 Manager Node 派發落嚟嘅容器任務,佢自己唔會參與 Raft consensus 呢類管理決策,所以可以專心做嘢,令到成個 分散式系統 更加有效率。
咁點樣實際加入一個 工作節點 呢?其實個核心就係一條 Docker CLI 指令。當你喺 Manager Node 度行完 docker swarm init 之後,個 terminal 通常會顯示一條好似 docker swarm join --token SWMTKN-1-xxxxx 192.168.1.100:2377 嘅命令。呢條就係 Worker Node 嘅「入場券」啦。你需要喺你想加入做 worker node 嘅另一部主機上面,確保已經安裝咗 Docker Engine,然後直接執行呢條命令就得。呢個 安全密鑰 係好重要嘅,佢確保只有受信任嘅主機可以加入 Swarm,唔會俾啲不明來歷嘅機器入侵你個 集羣管理 系統。
如果你唔記得咗條 join token 點算?唔使驚,好簡單。你隨時可以返去 Manager Node 度,用 docker swarm join-token worker 呢個指令,佢就會重新顯示返條完整嘅 docker swarm join 命令俾你抄。呢個設計對於 節點管理 好方便,尤其係當你要大規模加入幾十部 Worker Node 嘅時候,你只需要保管好 Manager 嘅安全,然後分發條命令就得。記住,Manager 同 Worker 嘅 token 係唔同嘅,用錯咗就加入唔到正確嘅角色啦。
成功加入之後,點樣確認呢?好簡單,你返去 Manager Node 度,行 docker node ls 呢個指令,你就會見到一個列表,顯示晒所有集羣裏面嘅節點。新加入嘅節點會喺度顯示,而且個 ROLE 欄會係 worker,STATUS 會顯示 Ready。呢個就係最基本嘅 集羣初始化 同 節點管理 操作。透過 Docker CLI,你可以好清晰咁掌握到成個 Swarm 嘅狀態,邊部機係 manager,邊部係 worker,一清二楚。
加入 Worker Node 之後,佢哋就可以即刻投入服務。當你透過 Docker Stack 或者 docker service create 去部署一個服務嘅時候,Manager Node 就會根據你設定嘅 服務副本 數量,自動將容器任務 編排 到唔同嘅 工作節點 上面運行。呢個就係 容器編排 嘅魔力,你唔需要手動指定邊個容器去邊部機,Swarm 會自動幫你處理好 服務部署 同調度,仲會自動監控住,如果某個容器死咗,佢會自動喺另一部健康嘅 worker node 上面重新啟動一個,確保服務唔會中斷。
喺實際應用上,加入 Worker Node 亦都要考慮到 網絡配置 嘅問題。所有加入 Swarm 嘅節點,無論係 manager 定 worker,都會自動建立一個 覆蓋網絡。呢個網絡係跨主機嘅,即係話,喺唔同 Worker Node 上面運行嘅容器,只要連接到同一個 overlay network,佢哋就可以直接用容器名互相溝通,好似喺同一部機上面咁方便。呢個對於 多容器部署 複雜應用(例如一個 Web App 連住一個 Database)係非常重要嘅,簡化咗好多 網絡配置 嘅麻煩。
最後都要提提安全同維護。雖然 Worker Node 唔使參與管理決策,但係佢哋同 Manager Node 之間嘅通訊都係經過 TLS 加密嘅,呢個係 swarm mode 預設嘅安全設定。另外,如果你將來需要將某個 Worker Node 升級做 管理節點,或者需要將某個節點暫時排出集羣進行維護,都可以透過 docker node promote 或 docker node demote 等指令嚟靈活管理。總而言之,熟練地加入同管理 Worker Node,係你掌握 Docker Swarm 呢個強大 容器集羣 工具嘅必修課,亦係實現現代化、彈性化基礎架構嘅基石。
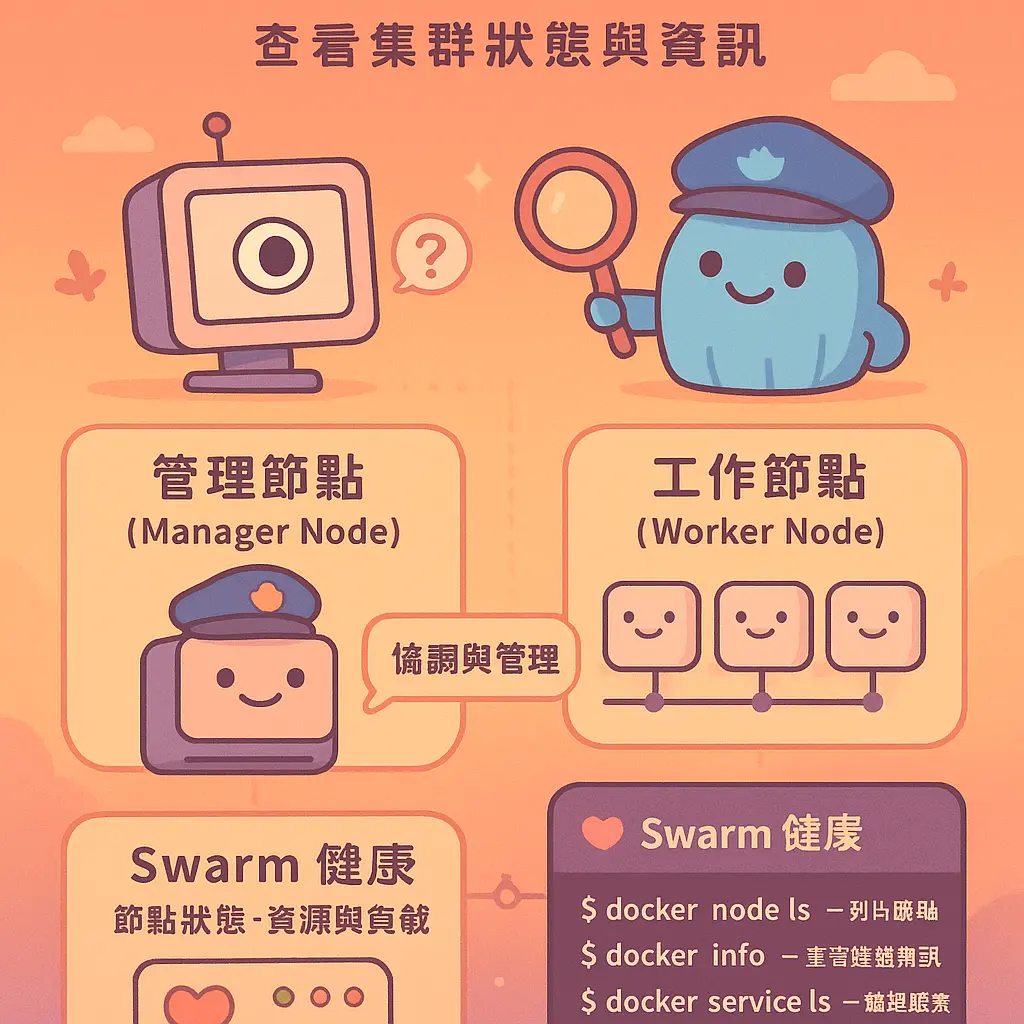
AboutDockerProfessional illustrations
查看集羣狀態與資訊
好啦,當你成功用 Docker Swarm init 建立咗個 容器集羣,下一步緊係要識得點樣「睇住個場」啦!查看集羣狀態與資訊 對於任何一個 集羣管理 嚟講,都係最基本功,就好似你睇住間舖頭個閉路電視一樣,要清楚知道邊個 管理節點 (Manager Node) 係度做緊嘢,邊啲 工作節點 (Worker Node) 仲有冇位,同埋整體個 Swarm 健康唔健康。呢個段落就同你深入講下,點樣用 Docker CLI 呢個強大工具,去掌握你個 分散式系統 (distributed system) 嘅一舉一動。
首先,最簡單直接嘅指令就係 docker node ls。你一打落去,個 Docker Engine 就會俾張清單你,列出晒所有加入咗呢個 Swarm 嘅節點。呢張清單好重要㗎,你會一眼睇到每個節點嘅:
HOSTNAME:部機本身叫咩名,通常用嚟識別。 STATUS:個節點而家係 Ready(準備好做嘢)定係 Down(死咗機或者斷咗線)。如果見到有節點 Down 咗,你就要即刻檢查吓網絡或者部機本身係咪有問題。 AVAILABILITY:呢個狀態係講個節點「可唔可以接受新任務」。Active 即係正常運作;Pause 就係暫停,唔會派新嘅 Docker 服務 或者容器俾佢,但現有嘅會繼續行;Drain 就係排水模式,通常係維護前用,會停止該節點上所有任務,並將佢哋遷移到其他 Active 嘅節點,確保服務唔中斷。 MANAGER STATUS:呢欄就話你知邊個係 Manager Node。如果寫住 Leader,就係現任「話事人」,負責 Raft 共識 (Raft consensus) 嘅決策同協調;寫住 Reachable 嘅就係其他有投票權嘅管理節點,用嚟做高可用性,就算 Leader 死咗,佢哋都可以選舉出新領袖;如果係空嘅,嗰個就係 Worker Node,純粹做執行工作。
舉個實例,假設你個集羣有 3 部機,1 個 Manager(Leader)同 2 個 Worker。你用 docker node ls 就會見到清晰嘅畫面,知道邊部機係大佬,邊部係細嘅。呢個係做 節點管理 (node management) 同故障排查嘅第一步。
淨係睇節點清單當然唔夠啦,你想深入睇某一個特定節點嘅詳細資訊,就要用 docker node inspect [節點ID或名稱]。呢個指令會彈出一大段 JSON 格式嘅詳細資料,對於進階管理同埋用 YAML配置 去做自動化好有用。入面會包括:
節點嘅完整 ID 同標籤 (Labels):標籤好有用㗎,你可以幫唔同嘅 工作節點 打標籤,例如「GPU機器」、「高記憶體」,然後部署 Docker 服務 嘅時候,就可以指定個服務一定要行喺有某個標籤嘅節點上,做到精細化嘅 服務部署。 節點嘅角色 (Role):清楚寫明係 manager 定係 worker。 主機嘅系統資訊:例如用緊咩 Linux 版本、CPU 有幾多核、總記憶體有幾多,呢啲資料對於做資源規劃同 負載均衡 好有參考價值。 節點嘅狀態:除咗基本狀態,仲會顯示佢係幾時加入 Swarm 嘅。 平台資訊:例如部機係 x86_64 定係 ARM 架構,對於部署跨平台嘅鏡像好重要。
如果你覺得 inspect 出嚟嘅 JSON 太 raw,想睇啲重點資訊,可以用 --pretty 參數,令到輸出易讀啲。例如 docker node inspect self --pretty 就可以用靚仔格式睇返自己當前節點嘅資訊。
另一個極之重要嘅查看角度,就係睇吓個 Swarm 本身嘅狀態同配置。指令係 docker info。當你身處 swarm mode 之下,docker info 嘅輸出會多咗一個 Swarm 專屬嘅段落。呢度你會睇到:
集羣嘅 ID:整個 Swarm 嘅唯一識別碼。 集羣嘅狀態:目前是否處於活躍的 容器編排 (container orchestration) 狀態。 節點總數:有幾多個 Manager 同幾多個 Worker。 管理者嘅 Raft 設定:例如 Raft 嘅心跳間隔、選舉超時時間等,呢啲係關乎到 集羣管理 高可用性嘅核心參數,一般唔使改,但了解佢有助你明白背後嘅運作原理。 集羣嘅證書資訊:包括 安全密鑰 (security tokens) 同 證書管理 嘅到期時間。Swarm 內部節點通訊係用 TLS 加密嘅,所以要留意證書幾時過期,避免成個集羣因為證書過期而癱瘓。
最後,唔好忘記我哋部署上去嘅服務本身。要睇 Docker 服務 嘅狀態,要用 docker service ls。佢會列出所有由你(或者用 Docker Stack 透過 docker-compose 檔案)部署嘅服務,每個服務有幾多個 服務副本 (replicas),個鏡像係咩,同埋喺邊個端口做緊 端口映射。想再睇詳細啲,例如每個副本具體行緊喺邊個節點上,就要用 docker service ps [服務名稱]。呢個指令對於追蹤某個服務係咪順利咁分佈到唔同嘅 工作節點,或者某個副本點解成日重啟,係不可或缺嘅工具。
總括嚟講,熟練運用呢幾個 Docker CLI 指令,你就好似有個控制台喺手,可以實時監控你個 Docker Swarm 集羣嘅心跳。由宏觀嘅節點分佈,到微觀嘅單一服務副本狀態,再到集羣本身嘅安全配置,全部一目了然。呢啲資訊係你之後進行擴縮容、滾動更新、故障恢復同埋規劃 覆蓋網絡 (overlay network) 同 網絡配置 嘅基礎,絕對係管理一個健壯 容器集羣 嘅必修課。
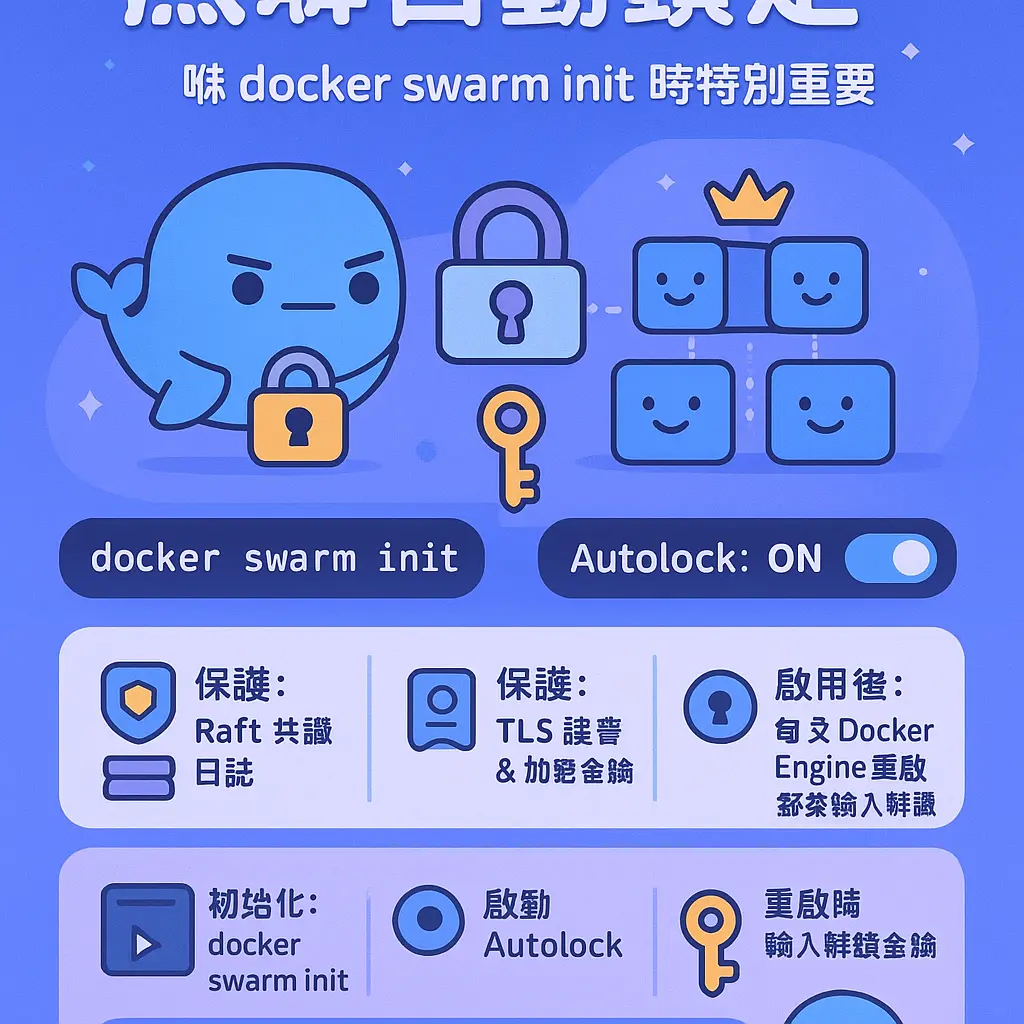
AboutServiceProfessional illustrations
集羣自動鎖定 (Autolock) 設定
講到 Docker Swarm 集羣安全,集羣自動鎖定 (Autolock) 呢個設定真係唔可以唔識。當你喺 2026 年用 Docker CLI 去初始化一個 Swarm 集羣嗰陣,例如行 docker swarm init,你可能會留意到有個關於 Autolock 嘅選項或者後續設定。咁究竟呢個功能做乜嘢?簡單嚟講,佢係為咗保護你個 Swarm 入面嘅 Raft 共識日誌 (Raft consensus logs) 同埋入面嘅敏感資料,例如 TLS 證書同加密金鑰。當你啟動 Autolock 之後,每次 Docker Engine 重啟,都要你提供一個預先設定好嘅解鎖金鑰,先可以重新啟動 Swarm 管理節點嘅服務。呢個設定對於保護你嘅 容器集羣 免受未經授權嘅存取,尤其係實體機或者虛擬機被人接觸到嘅情況,係非常重要嘅一環。
點解需要咁做?想像一下,你個 Swarm 集羣入面有幾個 管理節點 (Manager Node) 同多個 工作節點 (Worker Node),所有節點之間嘅通訊同 服務部署 協調都靠 Raft 日誌。呢啲日誌入面包含咗集羣嘅狀態同埋用嚟加密節點間通訊嘅 TLS 金鑰。如果冇啟用 Autolock,當有人可以直接存取到某個管理節點嘅檔案系統(例如個 Server 被人偷咗或者入侵咗),佢就有可能攞到呢啲金鑰,從而冒充集羣嘅一員,甚至控制成個 分散式系統 (distributed system)。所以,Autolock 就等於為你個 Swarm 加多一道實體門鎖,即使硬件被人攞到,冇條解鎖匙都係入唔到。
設定 Autolock 有幾個方法。最直接係喺初始化集羣嗰陣就做,你可以用 docker swarm init --autolock 呢個指令。執行之後,Docker Engine 會即時生成一條解鎖金鑰(通常係一長串字元),你一定要將呢條金鑰安全地保管好,例如用密碼管理工具存起,或者列印出嚟鎖入保險箱。記住,呢條匙同你集羣嘅身家性命一樣重要!如果你初始化嗰陣冇開啟,後續都可以用 docker swarm update --autolock=true 呢個指令去啟動佢,同樣地,系統會生成一條新嘅解鎖金鑰俾你保存。
噉實際操作係點?假設你已經有個運行緊嘅 Swarm 集羣,入面有齊管理節點同工作節點,負責緊一啲 Docker 服務 (Docker Service) 或者用緊 Docker Stack 透過 YAML 配置檔去部署多容器應用。你發現安全要求要提高,於是決定啟用 Autolock。你喺其中一個管理節點上面,用 Docker CLI 執行更新指令。完成之後,你試下重啟吓個 Docker Engine 服務。噉時候你就會發現,個 Swarm 管理服務唔識自己啟動返,佢會停咗喺度,等你用 docker swarm unlock 呢個指令,然後貼返條解鎖金鑰入去。輸入正確,成個集羣管理功能先會恢復正常,節點管理 同 服務編排 先可以繼續運作。呢個過程確保咗,就算部機 reboot 咗,都要有授權人士(即有條匙嘅人)介入先可以令集羣運作。
對於日常維運有乜嘢影響?首先,團隊一定要有清晰嘅金鑰管理流程。其次,所有會導致 Docker Engine 重啟嘅操作,例如系統更新、主機遷移,甚至係簡單嘅 reboot,都要預留時間同有授權人員去輸入解鎖金鑰。如果唔係,個管理節點就會「鎖住」,令到成個集羣嘅 集羣管理 功能(例如發佈新服務、擴縮容)停擺。不過要留意,Autolock 只鎖住管理節點嘅 Raft 日誌同加密資料,已經運行緊喺工作節點上面嘅 容器服務 同 服務副本 理論上會繼續運行,因為佢哋嘅運作指令已經落咗去。但係如果呢個時候有工作節點離線或者需要調度新任務,就可能會因為管理平面被鎖而出現問題。
最後都要提提風險同最佳實踐。萬一你真係唔見咗條解鎖金鑰點算?呢個情況係有方法處理,但係非常麻煩同有風險。你可以用 docker swarm unlock-key --rotate 呢個指令去輪換一條新嘅金鑰,但前提係你仲可以喺未重啟嘅管理節點上執行到指令。如果所有管理節點都重啟咗而且被鎖住,噉你就需要喺每個管理節點手動停止 Swarm 模式,然後重新加入集羣,過程會好複雜而且可能導致服務中斷。所以,千祈唔好睇小金鑰保管呢一步。喺 2026 年嘅環境,結合埋其他安全措施,例如嚴格嘅 Linux 主機保安、網絡配置入面用好 覆蓋網絡 (Overlay Network) 嘅加密功能、同埋妥善管理 安全密鑰,先可以話你個 Docker Swarm 集羣係一個真正安全同可靠嘅 容器編排 平台。
AboutDocker服務Professional illustrations
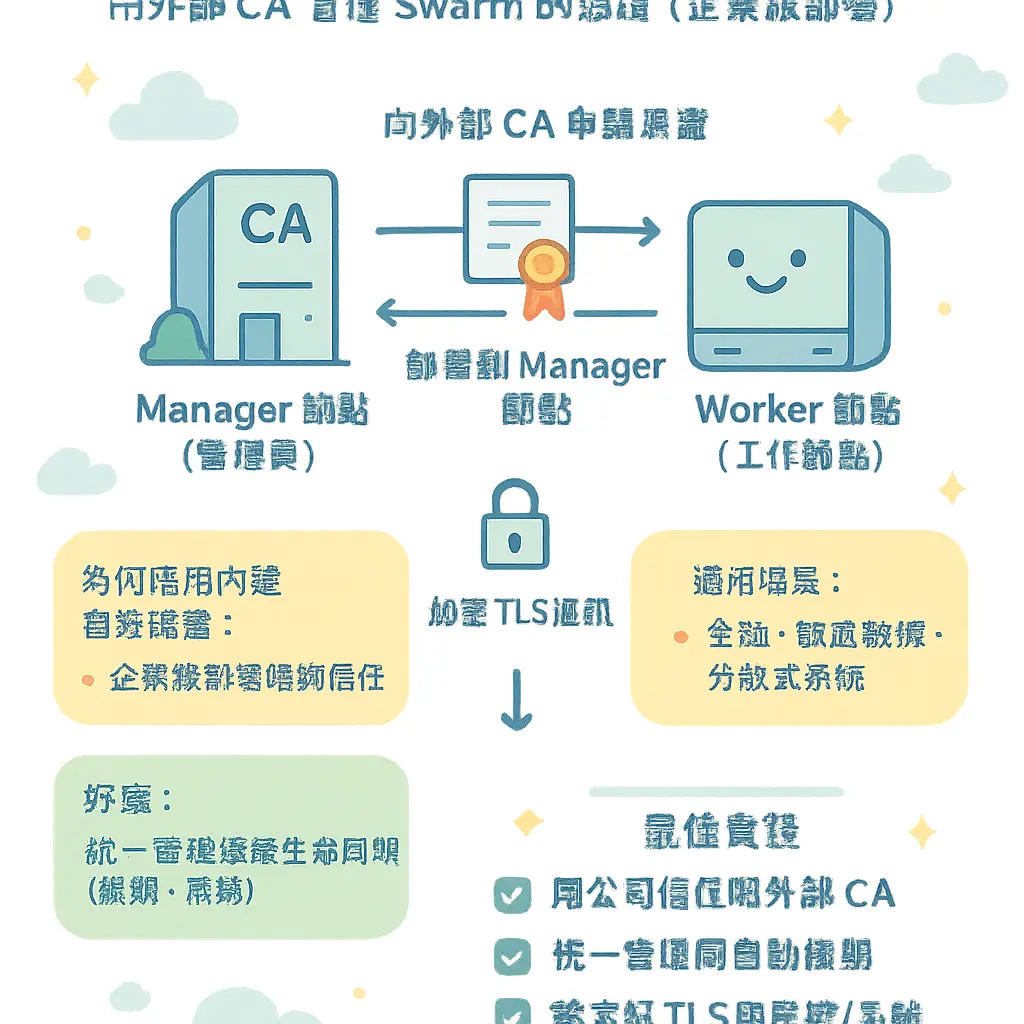
外部 CA 證書整合
好啦,講到 Docker Swarm 嘅集羣管理,特別係 Swarm 入面嘅 manager node 同 worker node 之間嘅溝通,安全性絕對係重中之重。喺 2026 年嘅今日,企業級部署已經唔會再用返 Swarm 自己生成嘅內部自簽證書喇,因為喺真實嘅 container orchestration 環境,尤其係金融或者處理敏感數據嘅 distributed system,整合外部 CA 簽發嘅證書先係標準做法。咁做嘅好處好明顯,你可以用返公司本身信賴嘅憑證機構,統一管理證書管理嘅生命周期,包括續期同吊銷,令到成個容器集羣嘅 TLS 通訊更加符合安全審計要求。簡單啲講,就係將 Docker Engine 之間嘅加密連線,交俾好似 Let's Encrypt、或者企業內部嘅 Private CA 呢啲權威機構去擔保,咁先至叫做專業。
咁點樣實際去做呢個外部 CA 證書整合呢?關鍵就在於你用 docker swarm init 或者後續配置嘅時候,要指定幾個重要參數。唔好再用 docker swarm init 就搞掂嘅思維,你要預先準備好由你嘅外部 CA 簽發嘅一組證書同私鑰,通常包括:CA 嘅根證書、Swarm 節點嘅服務器證書同對應私鑰。跟住,你需要喺初始化 Swarm 或者加入節點時,透過 Docker CLI 設定相關路徑。例如,你可以喺 manager node 上,透過修改 Docker daemon 嘅配置(通常係 /etc/docker/daemon.json)去指定外部證書,然後先再初始化集羣。不過要留意,呢個動作最好喺建立 Swarm 之前就設定好,因為涉及到底層 Docker Engine 嘅 TLS 設定。
呢個整合過程,直接影響到集羣初始化同後續節點管理嘅每一個環節。當你嘅 manager node 用緊外部 CA 證書,任何要加入集羣嘅新節點,無論係 worker node 定係額外嘅 manager node,都必須信任同一個外部 CA。呢個就係點解統一證書管理咁重要,如果唔係,節點之間就建立唔到信任,無法加入 Swarm 參與服務部署。特別係當你嘅集羣橫跨唔同嘅雲端或者數據中心,呢種基於共同信任鏈嘅設計,確保咗覆蓋網絡同 Raft consensus 算法通訊嘅安全性,防止中間人攻擊。記住,Swarm 嘅 Raft 日誌儲存咗集羣狀態嘅敏感資訊,管理節點之間嘅通訊加密絕對不能馬虎。
對於日常運維,用外部 CA 證書亦都簡化咗安全密鑰嘅輪換程序。你唔使再登入每一部 Linux 主機去手動替換 Swarm 內部生成嘅證書,而可以透過你公司嘅證書管理系統,自動化咁分發同更新證書到所有 Docker Engine 節點。當證書就快到期,你只需要用新證書重新配置 Docker daemon 並重啟服務,集羣喺短暫震盪後就會恢復正常。呢種做法比起處理 Swarm 內部嘅過期證書危機,要來得從容同可控得多。當然,喺設計 Docker Stack 嘅 YAML配置 時,你亦都可以為特定嘅 Docker服務 設定額外嘅 TLS 驗證,但底層集羣通訊嘅證書,就係靠呢套外部 CA 整合來奠定基礎。
最後都要提一提常見嘅陷阱。有啲管理員可能只係替換咗一部分節點嘅證書,導致集羣出現分割,一啲節點無法同步狀態。所以,整合外部 CA 最好喺規劃集叢初期,或者預留維護窗口一次性全面更換。另外,確保你嘅外部證書嘅 Subject Alternative Name 包含咗節點嘅主機名或者 IP,符合 Docker Swarm 嘅驗證要求。總而言之,將外部 CA 證書整合視為你 Swarm 集羣安全架構嘅核心一環,唔好當佢係後期附加功能。咁樣先能夠確保你嘅多容器部署、服務副本嘅調度、同負載均衡等容器編排功能,都建立喺一個堅固可信嘅安全層之上。
About容器集羣Professional illustrations
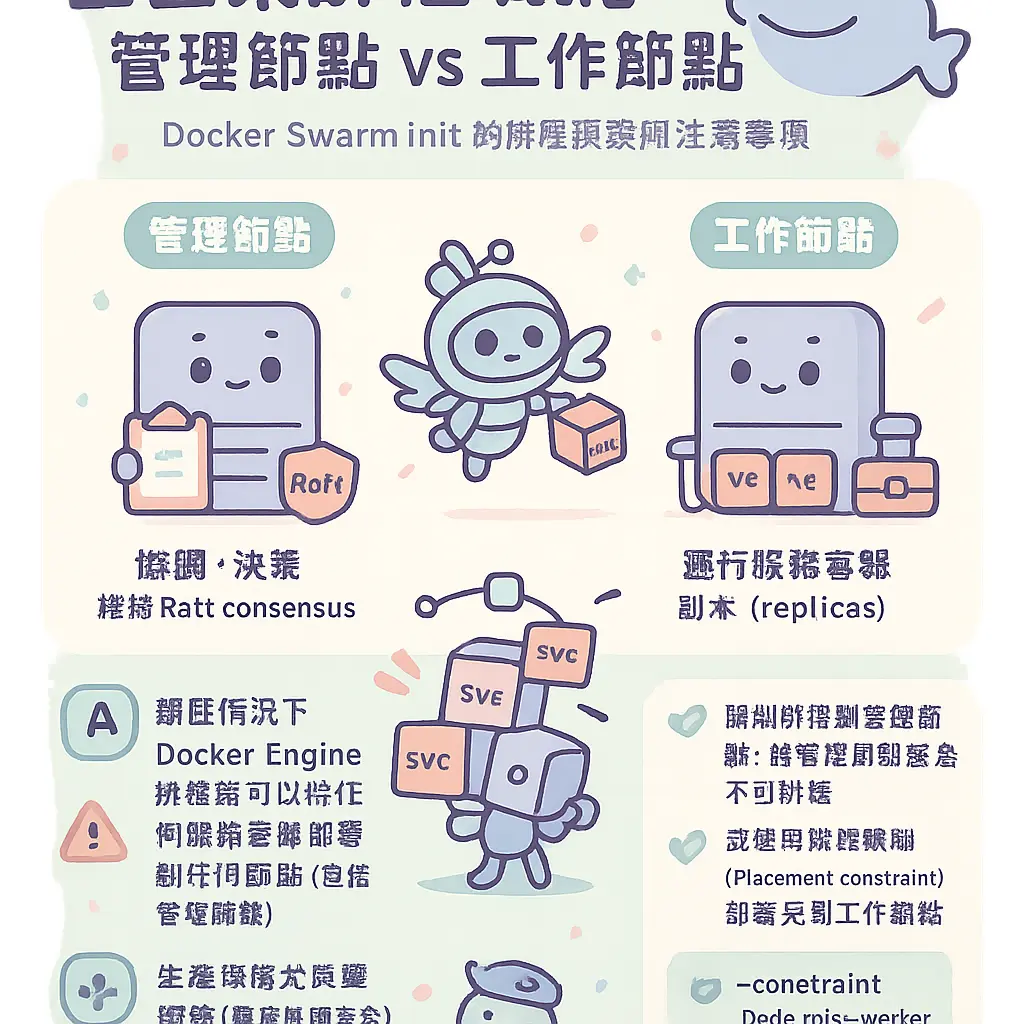
管理節點排程限制
講到管理節點排程限制,其實就係 Docker Swarm 入面一個好核心嘅進階管理概念。喺一個正常運作嘅 Docker 容器集羣裏面,我哋有管理節點同工作節點。管理節點嘅主要職責係負責成個集羣嘅協調同決策,例如維持 Raft consensus、處理 Docker 服務嘅排程指令、管理集羣狀態等等,而工作節點就係主力負責運行 Docker 服務入面嘅容器副本。咁問題就嚟啦:如果我哋唔做任何限制,Docker Engine 嘅排程器默認係可以將任何服務嘅容器,部署落任何節點度,包括管理節點本身!呢個設定對於細規模測試或者開發環境可能冇問題,但喺 2026 年嘅生產環境,尤其係講究穩定性同安全嘅分散式系統,咁樣做就好容易出事了。
點解要特登限制管理節點唔好跑業務容器呢?原因有幾個。第一,管理節點本身已經要處理集羣管理嘅重任,包括 Raft 共識算法嘅運行、Docker CLI 指令嘅處理、證書管理同集羣狀態同步。呢啲工作本身已經消耗 CPU 同記憶體資源,如果你再將一堆業務容器放上去跑,好容易就會令到管理節點負載過高,反應變慢,嚴重嘅甚至會影響 Raft 嘅心跳同選舉,導致成個集羣嘅管理平面不穩定,呢個絕對係容器編排上嘅大忌。第二,係出於安全同隔離考慮。管理節點掌握住成個 Swarm 嘅安全密鑰同控制權,如果呢個節點同時運行對外服務嘅容器,萬一容器被入侵,攻擊者就有更高機會接觸到集羣管理嘅敏感資料,風險大增。所以,最佳實踐就係要設定排程限制,明確禁止 Docker 服務將任務容器部署到管理節點上,確保管理平面同應用平面分離。
咁具體點樣設定呢個「管理節點排程限制」呢?主要可以透過兩個層面去實現。第一個層面,係喺初始化 Swarm 或者加入節點嘅時候,就明確設定節點嘅角色同可用性。當你使用 docker swarm init 去建立集羣,或者用 docker swarm join 加入節點時,每個節點本身已經被標記為 manager 或者 worker。但更重要嘅係,你可以進一步設定節點嘅「可用性」。透過 Docker CLI,你可以將管理節點嘅「排程可用性」設置為 drain。當一個節點處於 drain 模式,Swarm mode 嘅排程器就唔會再分配任何新嘅任務(即係容器)畀呢個節點,並且會將已經運行喺上面嘅任務,逐步遷移到其他可用嘅工作節點上。呢個操作非常適合用喺你要維護管理節點,或者明確禁止佢運行業務服務嘅時候。你可以用指令好似係 docker node update --availability drain NODE_ID 嚟達成。
第二個層面,就係喺部署 Docker 服務或者 Docker Stack 嘅時候,透過約束條件來精細化控制。呢個方法更加靈活。當你使用 docker service create 或者用 docker-compose.yml 檔案定義服務再透過 Docker Stack 部署時,你可以加入「放置偏好」或者「約束」。雖然我哋唔直接用代碼表示,但概念上你可以指定個服務只可以運行喺角色係 worker 嘅節點上,或者透過節點標籤嚟實現。例如,你可以為所有管理節點打上一個標籤,例如 node.role==manager,然後喺服務定義入面,設定一個約束條件,話明唔可以運行喺有呢個標籤嘅節點上。咁樣一來,無論你點擴展個集羣,服務嘅副本都只會喺工作節點上誕生。呢種方法結合咗節點管理同服務部署嘅策略,令到集羣管理更加清晰。
除咗基本限制,我哋仲可以點樣優化呢?喺 2026 年,我哋嘅思維可以更進一步。例如,考慮到高可用性,一個生產級嘅 Docker Swarm 集羣通常會有三個或五個管理節點,去分擔 Raft 共識嘅負載同防止單點故障。呢啲管理節點之間,本身已經有內部嘅覆蓋網絡用於通訊同數據同步。我哋嘅排程限制策略,應該要一視同仁咁應用喺所有管理節點上,確保冇一個管理節點會運行用戶容器。另外,網絡配置都係相關嘅一環。管理節點之間嘅通訊端口(例如 2377, 7946, 4789)需要保持暢通,如果管理節點同時運行大量業務容器,可能會因為端口衝突或者網絡擁塞而影響管理通訊。所以,設定排程限制,某程度上都係為咗保障集羣內部網絡配置嘅穩定性。
最後,都要提提實際操作上嘅注意位。當你將一個現有嘅、正在運行服務嘅管理節點設置為 drain 模式,Swarm 會優雅地終止上面嘅任務,並喺其他符合條件嘅工作節點上重新啟動它們。呢個過程會涉及服務嘅短暫中斷(取決於你服務嘅健康檢查同更新設定),所以最好喺維護窗口或者流量低峰期進行。同時,要記住管理節點排程限制係一個持續嘅管理動作。當你擴展集羣,加入新嘅管理節點時,要記得第一時間為佢設置好相應嘅標籤或者排程可用性,確保你嘅限制策略能夠持續生效。總而言之,妥善管理節點排程限制,係確保你嘅 Docker Swarm 容器集羣能夠穩定、安全、高效地進行負載均衡同服務部署嘅基石,絕對唔可以忽視。
About工作節點Professional illustrations
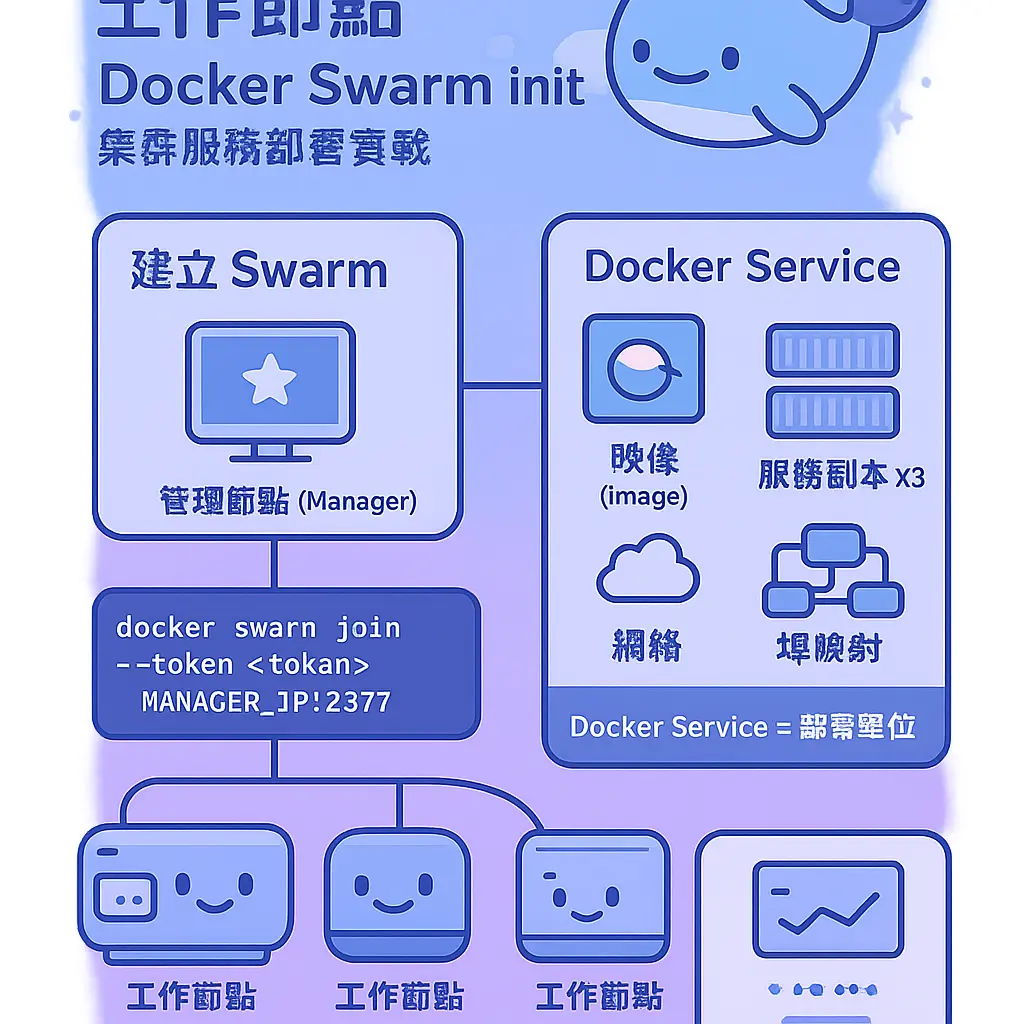
集羣服務部署實戰
好啦,講完咗點樣用 Docker Swarm init 去建立個 Swarm 同埋加 Worker Node 入去,我哋係時候要嚟啲真材實料嘅嘢啦,就係「集羣服務部署實戰」。呢個部分先係真正考驗你個 容器集羣 掂唔掂嘅時候。喺 Swarm mode 入面,最基本嘅部署單位就係 Docker Service,你可以當佢係一個你想運行嘅應用程式嘅藍圖,入面定義咗要用咩映像、要開幾多個副本(服務副本)、要用咩網絡、要映射咩埠等等。呢個概念同你單機玩 Docker 好唔同,因為你而家係面對緊一個 分散式系統,所有指令都係透過 Docker CLI 向 Manager Node 落,然後個 Manager Node 就會透過 Raft consensus 算法同其他 Manager 協調好,再將任務分配俾啲 工作節點 去做。
咁點樣開始部署第一個服務呢?最直接嘅方法就係用 docker service create 呢個指令。舉個例,你想部署一個 Nginx 網頁伺服器,並且想佢有 3 個副本,同時將宿主機嘅 8080 埠映射到容器嘅 80 埠,你就可以咁樣打指令。呢個指令一落,Swarm 嘅 容器編排 引擎就會立即開工,佢會睇吓邊啲 Worker Node 仲有資源,然後喺上面拉取 Nginx 映像並啟動容器。你可以用 docker service ls 去睇吓服務嘅狀態,再用 docker service ps <服務名> 去睇埋每個副本具體被安排咗去邊個節點度行緊,呢個就係最基本嘅 節點管理 同 服務部署 操作。呢個過程仲會自動幫你設定好內置嘅 負載均衡,即係所謂嘅 Swarm 內建 Load Balancer,你只需要訪問任何一個 Swarm 節點嘅 IP 同 8080 埠,佢就會自動將請求分發去其中一個運行緊嘅 Nginx 容器,完全唔使你自己額外設定,對於快速部署同擴展服務真係好方便。
不過,用命令行逐個參數去打,對於複雜嘅多容器應用嚟講就好易出錯同難管理啦。所以,實戰中更高階同主流嘅做法,就係使用 Docker Stack。Docker Stack 其實係建基於 docker-compose 檔案嘅一個 集羣管理 工具,你可以用一個 YAML 格式嘅 YAML配置 檔案,去定義晒成個應用程式堆棧(Stack)入面所有嘅 Docker服務、網絡配置 同埋 Volume 設定。呢個方法對於做 多容器部署 嚟講,管理上真係清晰同方便好多。例如,你有一個 Web 應用,需要一個前端服務、一個後端 API 服務同一個數據庫,你就可以將佢哋全部寫喺同一個 docker-compose.yml 檔案度,定義好彼此之間嘅依賴關係同埋共用嘅 覆蓋網絡。呢個 覆蓋網絡 好重要,佢會自動喺成個 Swarm 集羣度建立一個虛擬網絡,等所有服務嘅容器,無論佢實際運行喺邊個 Worker Node 上面,都可以透過服務名互相溝通到,完全抽象化咗底層嘅物理網絡。
寫好個 compose 檔案之後,點樣部署上 Swarm 呢?好簡單,就用 docker stack deploy -c docker-compose.yml
當然,實戰部署仲有好多細節要考慮。例如 網絡配置,除咗用預設嘅 覆蓋網絡,你可能需要為某啲服務設定特定嘅 端口映射 模式(例如 host mode 以獲得更好嘅網絡性能)。又例如 證書管理 同 安全密鑰,如果你嘅服務之間需要 TLS 加密通訊,或者需要存取私密嘅 Registry,你就要事先喺 Swarm 度建立好相應嘅 Secret 同 Config 物件,然後喺 compose 檔案度掛載入容器。另外,資源限制(CPU、記憶體)同服務更新策略(更新延遲、并行更新數量、失敗時回滾)等等,都係喺 YAML 檔案度可以仔細定義嘅項目,呢啲設定對於確保生產環境嘅穩定性同可預測性係至關重要。總括嚟講,集羣服務部署實戰 就係將你對 Docker Swarm 嘅認知,透過 Docker CLI 同 Docker Stack 轉化成實際運行、可擴展同高可用嘅服務,只要你掌握好服務同堆棧呢兩個核心概念,就能夠駕馭到呢套強大嘅 容器編排 系統。
About管理節點Professional illustrations
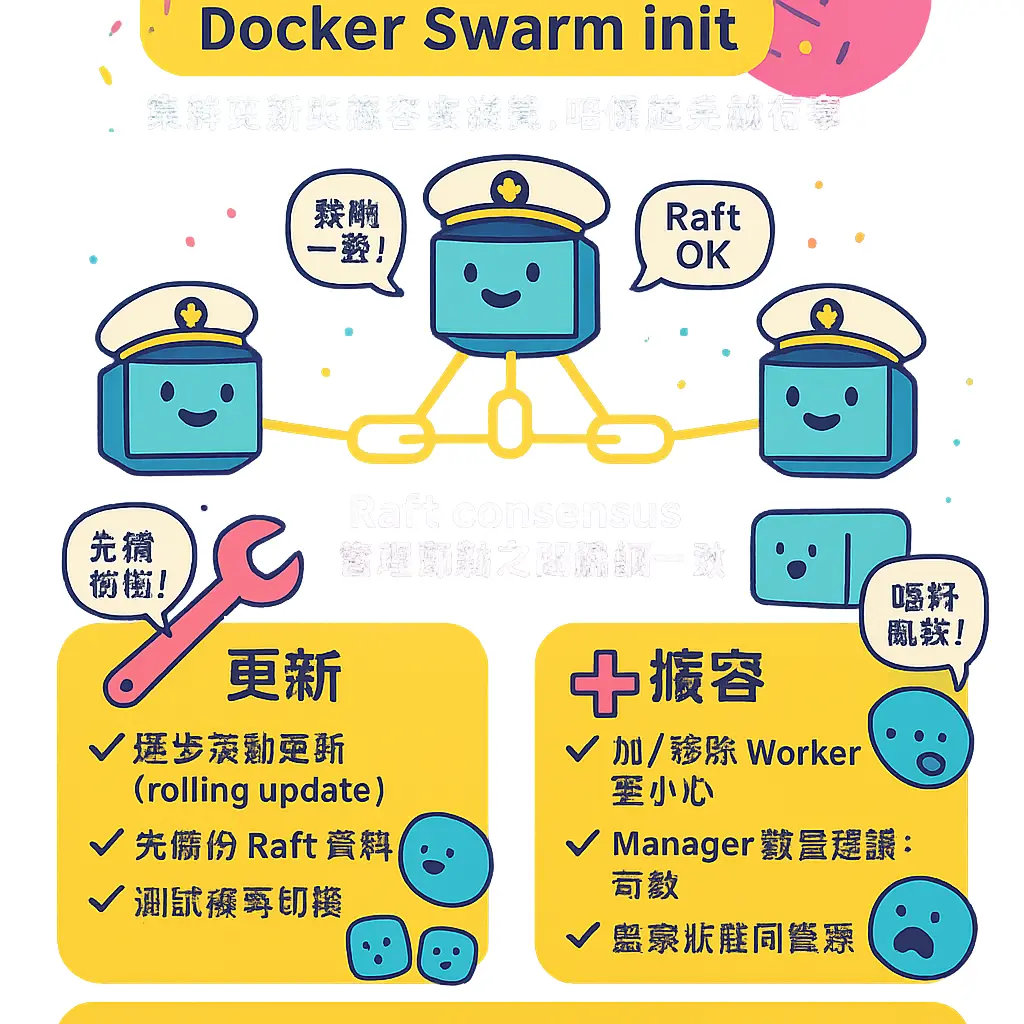
Swarm 集羣更新與擴容
好啦,而家講到 Docker Swarm 集羣嘅更新同擴容呢個實際操作環節,呢度先係真正考驗你個集羣管理功力嘅時候。好多師兄一開始以為用 Docker Swarm 起好個 集羣 就搞掂,其實個 容器集羣 係要「養」嘅,業務量會變,服務版本要升級,呢啲都涉及到點樣安全又順暢咁去更新同擴充你個 Swarm。首先,你要清楚知道,Swarm 嘅核心係一套 分散式系統,佢嘅狀態係由 Manager Node 之間通過 Raft consensus 算法來協調一致嘅。所以,任何對集羣結構嘅改動,例如增加或者移除 Worker Node,又或者升級 Docker Engine 版本,都唔可以亂咁嚟,一定要有策略。
講到擴容,最常見就係加 工作節點 落去個 Swarm 度。假設你公司個網站流量突然爆升,原本嗰幾部 Worker Node 頂唔順,你就要加機。用 Docker CLI 做呢件事好簡單,喺新機上面安裝好最新版嘅 Docker Engine,然後用當初集羣初始化時生成嘅 join token(安全密鑰) 去執行 docker swarm join 就得。記住,token 分兩種,一種係 for Manager Node,一種係 for Worker Node,千祈唔好搞亂,否則會影響 Raft 羣組嘅穩定性。加完節點之後,個 Swarm 嘅負載均衡機制就會自動將新嘅 Docker 服務 任務調度過去,唔使你再手動搞。不過,我建議加完節點後,最好用 docker node ls 睇清楚個節點狀態係唔係 Ready,同埋留意下佢嘅 Docker Engine 版本同集羣主流版本係咪兼容,避免出現奇怪問題。
另一種擴容,係針對服務本身嘅服務副本數量。呢個就更加家常便飯啦。譬如你運行緊一個 web server 嘅 Docker Service,最初可能只係開咗 3 個副本,但係發現反應唔夠快。咁你就可以直接用 docker service scale 指令,即時將副本數增加到 10 個甚至更多。Swarm 嘅 容器編排 引擎會自動喺成個集羣嘅節點(包括新加嘅節點)上面,幫你拉取鏡像、啟動容器,並且配置好 覆蓋網絡,等所有副本都可以通過同一個網絡配置互相溝通同被訪問。呢個過程係滾動進行嘅,對服務嘅影響好細。如果你係用 Docker Stack 通過一個 YAML配置 文件來部署一堆相關服務(即係 多容器部署),咁你直接去修改 YAML 文件裏面個 replicas 數值,然後再用 docker stack deploy 重新部署一次就得,佢會智能咁只更新有變動嘅部分。
跟住落嚟係重頭戲:集羣更新。更新又分幾種,第一種係節點本身嘅 Docker Engine 版本升級。呢個要一步步嚟,最好先升級 Worker Node,最後先升級 Manager Node。升級前,可以先將目標節點設為 Drain 狀態,等 Swarm 將上面運行緊嘅任務逐個遷移到其他節點,清空咗之後先至進行升級操作,搞掂再設返做 Active 狀態。對於 Manager Node,更要逐個升級,確保 Raft 集羣始終有過半數嘅管理節點在線,唔會丟失領導權。第二種更新係服務嘅鏡像版本升級,即係我哋常講嘅滾動更新。你用 docker service update 指令可以好靈活咁控制,例如指定新嘅鏡像標籤、更新嘅批次間隔時間、失敗時點樣回滾等等。呢個就正正體現咗 容器編排 嘅優勢,你可以做到零停機更新,用戶完全感覺唔到。例如,你設定每次更新 2 個副本,等新副本健康檢查通過後,再更新下一批,好安全。
最後都要提提,無論係擴容定更新,都要密切監察住集羣嘅狀態。Docker CLI 提供咗好多實用指令,好似 docker service ps 睇服務任務分佈,docker node ps 睇節點任務,docker network ls 檢查 網絡配置 等等。特別係當你改動 YAML配置 再用 Docker Stack 部署時,一定要理解清楚佢個聲明式更新嘅邏輯,避免配置寫錯導致意外後果。總而言之,將 Swarm 集羣嘅更新與擴容當成一個常規運維動作,規劃好流程,用好工具,你個 容器集羣 就可以又彈性又穩定咁支持業務發展啦。記住,節點管理 同 服務部署 係相輔相成嘅,管理好節點資源,先可以讓服務擴縮容更加得心應手。
AboutswarmProfessional illustrations
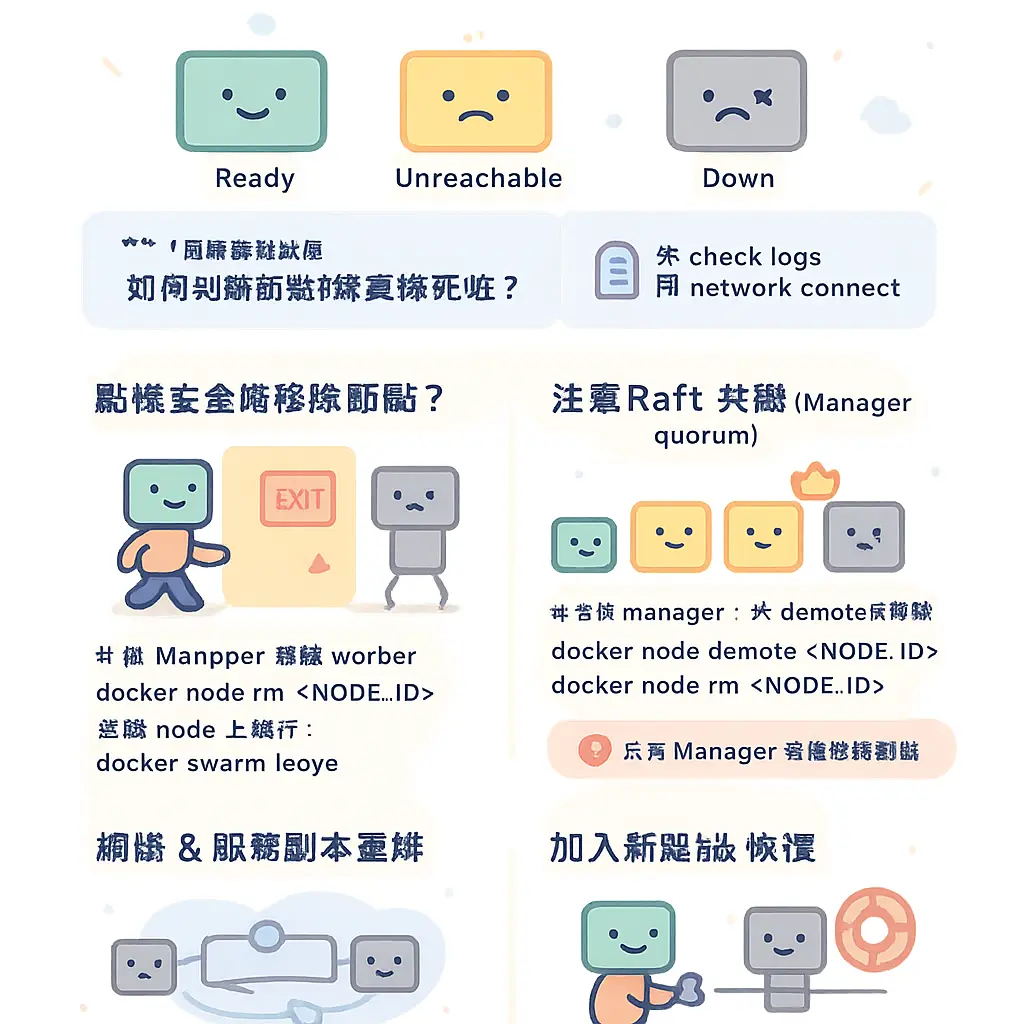
故障排除與節點移除
好喇,而家我哋嚟傾下Docker Swarm集羣管理入面,最實際亦都最易遇到嘅問題:故障排除與節點移除。喺真實環境管理一個容器集羣,無論你係用緊幾部Linux主機定係一個龐大嘅分散式系統,工作節點(Worker Node)或者管理節點(Manager Node)出問題要踢走或者更換,係家常便飯。呢個過程唔單止係打句command咁簡單,背後涉及Swarm mode嘅Raft共識算法、網絡配置同埋服務副本嘅重新調配,一唔小心處理就會影響到成個集羣嘅穩定性同埋你部緊嘅Docker服務。
首先,點樣判斷一個節點係咪真係「死咗」需要移除呢?喺Docker CLI度,你可以用 docker node ls 嚟睇吓集羣入面所有節點嘅狀態。如果一個工作節點(worker node)顯示為 Down 或者 Unreachable,咁就係時候要行動。但係,喺行動之前,一定要搞清楚個問題係乜嘢。係網絡分區(Network Partition)問題令到管理節點(manager node)聯絡唔到佢?定係部機真係hang咗機,或者個Docker Engine停咗?如果只係暫時性網絡波動,你可以等一陣,或者檢查下覆蓋網絡(Overlay Network)嘅配置同埋防火牆規則。盲目移除節點可能會導致喺嗰個節點上運行緊嘅Docker服務任務(task)突然終止,雖然Swarm會嘗試喺其他健康節點上重新調配副本,但呢個過程會造成服務短暫中斷。
當你確定要移除一個節點,尤其是工作節點(worker node),步驟相對直接。首先,你需要登入到一個管理節點(Manager Node)上面,因為只有管理員節點先有權限去管理集羣成員。然後,用 docker node rm 指令跟住個節點嘅ID或者主機名嚟移除。例如,你發現有個叫 worker-02 嘅節點唔妥,就可以先將佢上面運行嘅任務疏散(drain)去其他節點。呢個疏散過程好重要,Swarm會將該節點設定為 Drain 狀態,停止接受新任務,並將現有任務優雅地停止並重新調配到其他可用嘅節點上,確保你嘅服務部署唔會因為少咗個節點而減少副本數量,維持到負載均衡。完成疏散後,先至正式執行移除指令。記住,移除節點並唔會自動刪除喺該節點上運行緊嘅容器,但因為服務任務已經被遷移,所以舊容器會變成孤兒,你需要手動清理。
如果出問題嘅唔好彩係一個管理節點(manager node),咁就麻煩少少喇。因為管理節點負責集羣管理同埋維護Raft日誌嘅一致性。一個Swarm集羣最少需要一個、建議有三個或以上嘅管理節點嚟實現高可用性。如果你只係得一個管理節點,佢死咗,成個集羣嘅管理功能就癱瘓咗(不過現有服務可能仲會繼續運行)。如果你有多個管理節點,其中一個死咗,你可以按照上述方法移除佢。但係,喺移除之前,必須確保集羣仲有足夠嘅管理節點(多數節點)去維持Raft consensus。例如,你原本有三個管理節點,死咗一個,咁你仲有兩個,仲可以運作。但如果你原本得兩個,死咗一個,咁你移除佢之後淨返一個,雖然仲可以運作,但已經冇咗高可用性,好容易因為呢個唯一管理節點故障而導致集羣管理癱瘓。所以,移除故障管理節點後,強烈建議你盡快用 docker swarm join-token manager 獲取新令牌,添加一個新嘅、健康嘅主機入嚟做管理節點,恢復集羣嘅韌性。
有時你可能會遇到更棘手嘅情況,就係節點無法優雅移除,例如部機完全無法連線,或者Docker Engine已經崩潰。呢個時候,你喺其他管理節點上嘗試 docker node rm 可能會失敗,或者個節點狀態一直卡住。對於呢種「殭屍節點」,你需要用 docker node rm --force 進行強制移除。但呢個係最後手段,要非常小心! 強制移除會直接從Swarm管理層面刪除該節點嘅記錄,但Swarm並唔會、亦都無法再去處理該節點上可能仲運行緊嘅任務。呢啲任務會一直顯示為 shutdown 或者 orphaned 狀態,你需要喺Docker Stack或Docker Service層面手動清理。強制移除亦可能對Raft日誌造成干擾,所以除非確定節點無法恢復,否則都係先嘗試修復網絡或重啟該節點嘅Docker Engine。
最後,提一提同節點移除相關嘅日常維護。無論係用純CLI定係結合 docker-compose 嘅YAML配置去部署服務,養成良好習慣都可以減少故障。例如,定期檢查節點嘅系統資源(CPU、記憶體、磁碟),更新Linux核心同Docker Engine到穩定版本,妥善管理Swarm嘅安全密鑰同埋證書(TLS certificates),避免因為證書過期而導致節點被集羣踢走。另外,設計服務時,利用好Swarm嘅容器編排能力,透過設定服務約束(constraints)或者偏好(preferences),將關鍵服務嘅副本分散喺唔同嘅物理節點或可用區,咁樣即使你需要移除某一個故障節點,對單個服務嘅影響都可以降到最低。總而言之,節點移除唔係一個獨立動作,而係一套由監控、判斷、準備(疏散)、執行到事後恢復嘅完整流程,做得好先可以確保你嘅容器集羣長治久安。